This blog is full of graphics.
A while ago I decided to try out the MySQL Cluster Auto Installer.
I have my own scripts and tools to work with MySQL Cluster so
I don't normally need to use it. But I wanted to know what it could
do and could not do. So I decided to take it for a spin.
I was actually positively surprised. It was very quick to get up and running.
Naturally as with any graphics tool it will get you to a point, if it meets issues
it can be hard to discover the issues. But there are ways to debug it as well
and naturally you have access to all MySQL log files as well as all the
NDB log files.
My personal takeaway is that the MySQL Cluster Auto Installer is a very good
tool for developing applications towards MySQL Cluster. For a production
installation I would probably want a bit more control over things and would
most likely write up some scripts for it. Also in a DevOps environment there
are other tools that can come in handy. But for a developer that wants to
develop an NDB API application or a MySQL application or any other
type of application in MySQL Cluster it seems a very good tool to get
MySQL Cluster up and running and shutting it down when ready for the
day.
We are working on some improvements of the Auto Installer, so if you have
opinions or bug reports referring to the Auto Installer please let us know
your preferences.
When I tried things out I used MySQL Cluster 7.5.4 and it worked flawlessly
on Mac OS X. On Windows there was some issues with my Windows installation
using Swedish and Windows uses the cp1252 character set which isn't compatible
with UTF-8. So I had to fix some conversion of some messages from Windows.
This bug fix is available in MySQL Cluster 7.5.5 that was recently launched.
The nice thing with a Python program was that to fix the bug one could simply edit
the script and run it again.
In this blog I will show you each step needed to get to a running MySQL Cluster
installation. I was personally able to perform the entire installation, definition of
the cluster, deploying the cluster and starting the cluster and waiting for this to
complete in 3 minutes and 50 seconds. Most likely for a newbie it will take a bit
longer, but with this blog as aid it should hopefully proceed very quickly.
This blog shows how to do this on my development machine which is running
Mac OS X. I also tested it on Windows and the steps are almost the same although
the Windows installer looks a bit different to the Mac OS X installer.
It should similarly be similarly easy to do this on Linux and Solaris.
My personal next step is to try out how it works to do a similar thing with
multiple machines. I have some Intel NUCs and some laptop running Linux that
should be possible to control from the Auto Installer in a similar fashion.
Developing a MySQL Cluster application definitely benefits from having a few
small servers in the background and Intel NUCs are a nice and cheap variant of
this that comes in at a very reasonable price.
After that I will also test the same thing but using some virtual machines in
the Cloud.
Description of the cluster you get up and running
After completing the below steps you will have MySQL Cluster up and running.
This will give you 2 MySQL Servers to access. Both of those MySQL Servers
can be used to both read and write all data. If you create a table in one MySQL
Server it will be present also in the other MySQL Server.
Some things such as views, triggers and functions are still per MySQL Server,
so you need to define them on each server.
So it is very easy to load balance your application towards those MySQL Servers
since they are all equal. The same would be true even if you had 100 MySQL
Servers. The actual data is stored in the data nodes but most of the processing
is done in the MySQL Servers.
You can also use the same setup to execute NDB API applications using a
low-level interface to MySQL Cluster that will in many cases have 10x
better performance but obviously also a higher development cost.
Another nice tool to develop applications with high performance using
the NDB API more directly is using ClusterJ which is a native Java
API towards MySQL Cluster. This interface is very easy to use
and uses an object-relational mapping.
Description of the steps
To download MySQL Cluster the easiest way is actually in my opinion to google it.
So MySQL Cluster Download in a google window will get you to the MySQL Cluster
download page quickly.
I am running this demonstration on a Mac OS X computer, so the download page
will automatically send me to the download page for MySQL Cluster on Mac OS X
I personally prefer the Mac installer image (.dmg file). The download of this will take
some time since it is about 400 MBytes. I am based in Sweden where 100 Mbit per
second download speeds are normal, so for me this takes about 1 minute.
After clicking Download I also need to click on one more page to get the download started.
While waiting for the download to complete I get a progress bar on the download on Mac OS X.
Once the download I open up the Downloads and click on the most recent download.
This will start up the installation process. The window below then pops up and I double
click on the package symbol.
Next I get a message about what I am doing with some references to further information.
I simply click Continue here.
Next the GPL license is presented to me, I click Continue.
I have to click Agree on that I agree to the usage terms described in the
GPL license.
Next before the actual installation starts I will be presented with the fact that this
will consume 1.6 GByte of my disk space. I click Install to start the Install.
On Mac OS X any new software install requires administrative privileges. So I get a
login window where I have enter my password to authenticate that I really want this
software installed. After typing the password I click Install Software.
After a short time the install is complete and I can click Close to finish the
installation.
Now we have managed to install MySQL Cluster. The next step is now to
start up the MySQL Cluster Auto Installer. This is a bit more involved but still
not that difficult. On Windows this can be started with a simple double-click
on the setup.bat file in the bin directory. On Mac OS X you need to start up
a terminal window to start the Web Server that drives the Auto Installer.
To start a terminal you go into the Launchpad and click on the symbol below.
Then click on the Terminal symbol and a terminal window will appear.
In the terminal window you change the directory to the bin directory of the
MySQL Cluster installation as can be seen in the window below. In this
directory you execute the Python program ndb_setup.py.
This Python Program starts a web server on the port 8081, if this port is already
used it will attempt with 8082, 8083 and so forth up until 8100 before it gives up.
Immediately after this web server has started it will launch a window in your
default browser.
In my case this is a Safari browser. I get a warning message that this isn't the
most well tested browser, however I have had no issues with using the
Safari browser so simply click Close here.
Now I get to the starting window of the MySQL Cluster Auto Installer.
I am doing my first installation so I will click on Create New Cluster.
I now get to the Define Cluster page. I define the hosts to use. Here I will
only run the tests on localhost, so only one host 127.0.0.1 is used.
I will use the simple testing variant that will use a part of my memory but not all.
If I run this on Windows I should also click away the use of SSH unless I want to
follow the instructions on how to use SSH on Windows. This is documented in the
MySQL Cluster Auto Installer manual.
When I am finished on the page I click Next.
Now the next page is pretty cool. The Web server has discovered where I have my
installation, it has found out which OS I am using, it has knowledge of how much
memory I have, it knows how many CPU cores I have and it proposes an installation
directory that I in this case will accept.
When I run this command on my Windows box I usually move the installation
directory to the D: disk instead of the C: since the C: disk is pretty full on my
Windows box.
Now we get to define the processes. The default in this case is one management server,
2 data nodes, 2 MySQL Servers and 3 API node slots (can be used to execute various
NDB tools or NDB API applications).
I see no specific reason to change so I click Next immediately.
Next I come to a page where I can edit the configuration before launching the start
of the cluster. On each node I can define Node Id, Data directory and Hostname if
I want to change those from the default.
If I click Show advanced configuration options and then click on Data layer I get
a chance to edit the MySQL Cluster configuration file. Here I can edit a multitude
of configuration parameters for MySQL Cluster although not all of them.
After I have finalised setting up the configuration I click Next. This brings
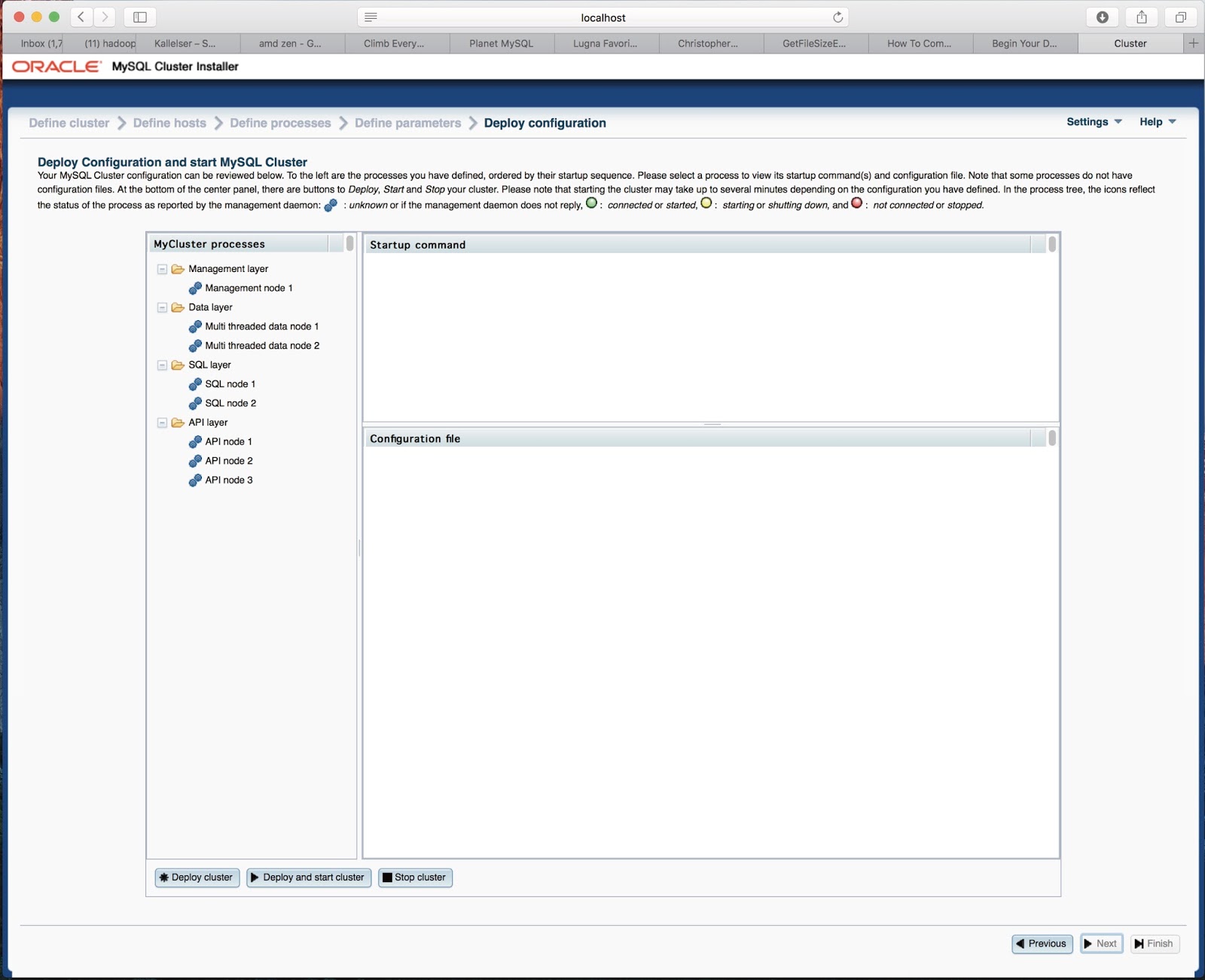
me to the Deploy and Start page.
I start by Deploying the cluster to get a chance to manually edit the configuration
files as well. If I don't care to edit those I can click Deploy and start cluster
which will also start the cluster immediately after deploying.
I only clicked Deploy cluster.
When the deployment of the cluster is completed I get a completed window,
simply click Close.
Now I go back to my terminal window and check what Deploy did.
In the Data Directory of node 49 (the management server) we find the
config.ini file. If I want to edit the MySQL Cluster Configuration file
further I can do that in this file before starting the cluster.
Next in the MySQL Server I have the my.cnf file and a couple of prepared
databases. If I want to edit the MySQL Server configuration further I can
do this in the my.cnf file.
There is no files in the Data Directory of the data nodes. This is created at
initial start of those nodes.
Now when I am done with the preparation I click Deploy and start cluster to
get the cluster started.
This presents me with a progress bar. It starts by starting the management
server. This goes so quickly that it wasn't possible to catch it.
Next it starts the data nodes. This take a bit of time, in my case about 30 seconds.
Next it starts the second data node.
Finally after starting all data nodes it will start the MySQL Server one at a time.
After starting the MySQL Servers the startup is complete. We click Close on the
information popup and then we have a page that also presents the state of each
node in the cluster based on what the management server sees.
Finally we can see the files now created in the management server and the Data
directory of the data nodes.
We now have a cluster with 2 data nodes, 2 MySQL Servers and 1 NDB
management server up and running.
You can access the MySQL Servers on port 3306 and 3307 as any
MySQL Server and start performing any test you want to apply for
your new MySQL Cluster installation.