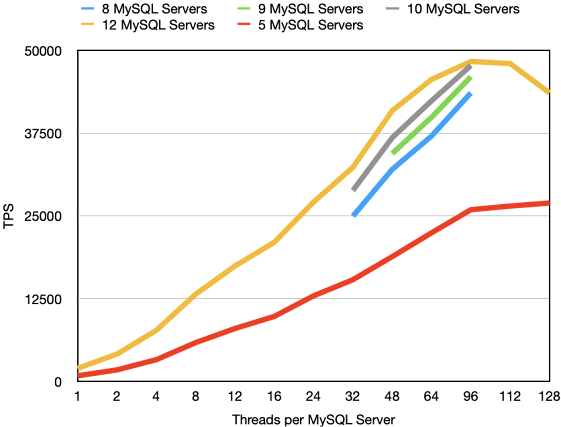
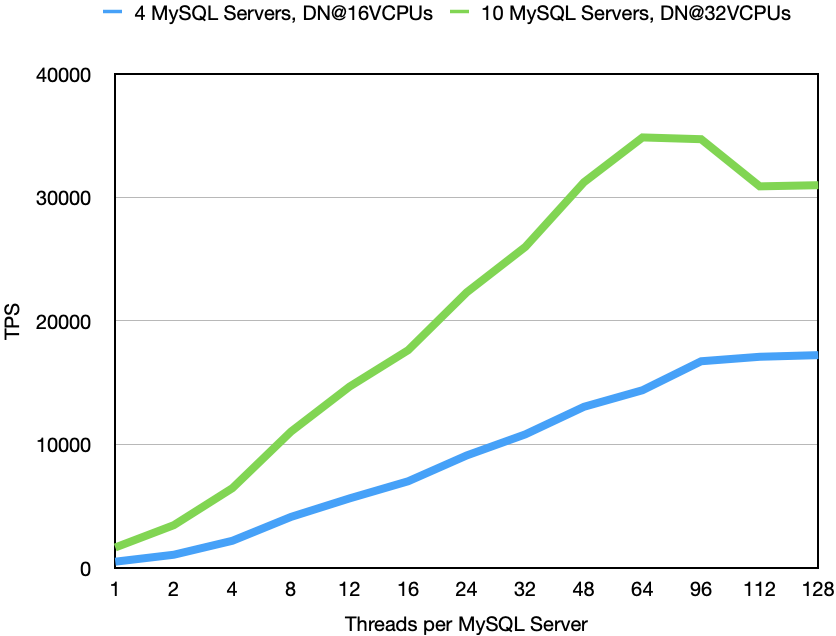
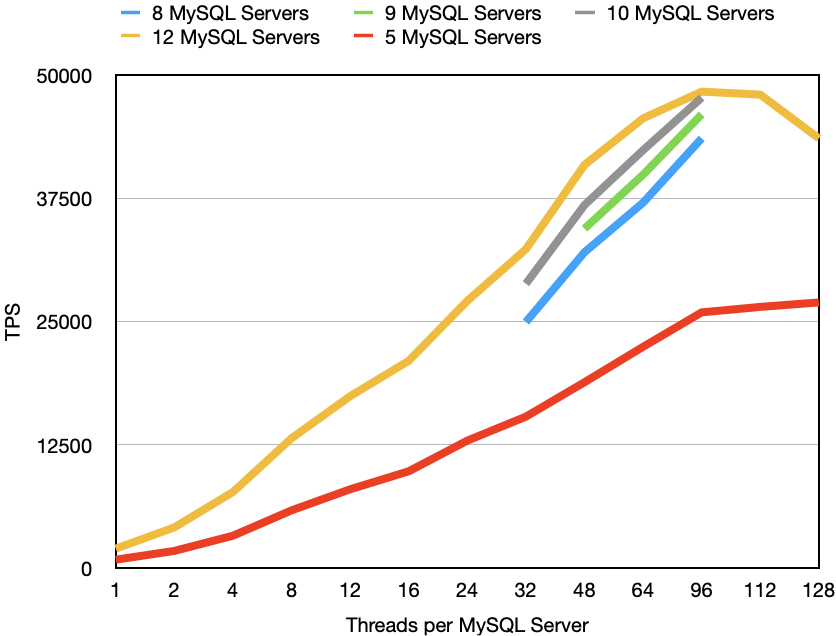
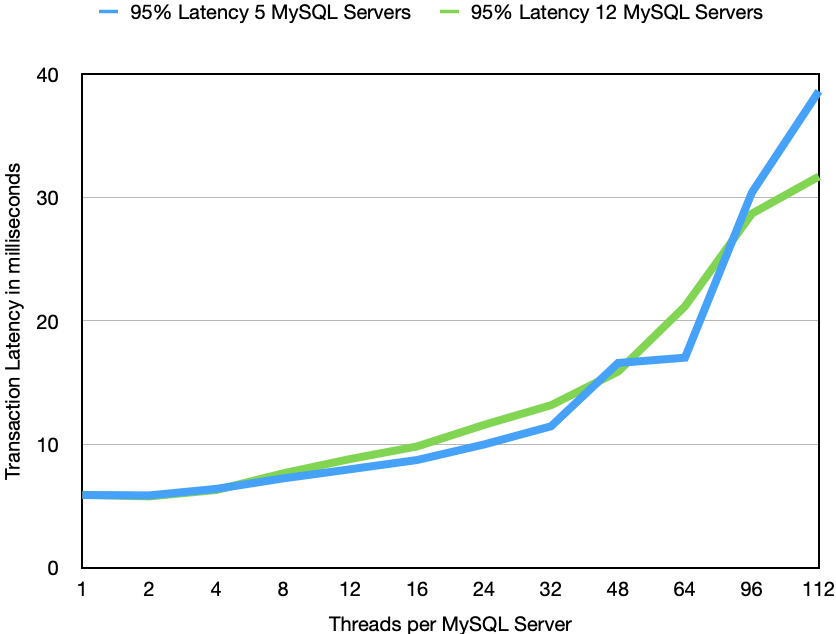
At Hopsworks we are working on ensuring that the online feature store will be able to perform complex join operations in real-time. This means that queries that could use data from multiple tables can be easily integrated into machine learning applications.
Today most feature stores use key-value stores like Redis and DynamoDB. These systems have no capability to issue complex join queries, if this is required the feature store will have to write complex code to handle this and this is likely to involve multiple roundtrips and thus cause unwanted latency.
Hopsworks feature store uses RonDB as its online feature store. RonDB can handle any SQL operations that MySQL can handle. Actually RonDB has even support for parallelising the join queries and pushing the filtering and joining down to the RonDB data nodes where data resides.
This means that users of the Hopsworks feature store can integrate more features from multiple feature groups in online inferencing requests. This means that things credit fraud detection can be made much more intelligent by taking more features into account in the inferencing requests.
This means that performance of real-time join queries becomes more important in RonDB. To evaluate how RonDB develops in this are I ran a set of tests using TPC-H queries from DBT3 against RonDB 21.04.17 and RonDB 22.10.4 (not released yet). I also ran tests against MySQL 8.0.35 (RonDB 22.10.4 is based on MySQL 8.0.35 with loads of added RonDB features).
The results were interesting, the improvement in Q20 was the highest I have seen in my career. The performance improved from 70 seconds to 80 milliseconds, thus an 875x speedup or 87500% improvement. Q2 had a 360x improvement. So RonDB 22.10.4 is much better equipped for more complex queries compared to RonDB 21.04. MySQL 8.0.35 had similar performance to RonDB 22.10.4 with an average of around 20% slower, this is mostly due to performance improvements in RonDB, not algorithmic changes.
When using complex queries the query optimiser tries to find an optimal plan, sometimes however better plans are available and one can add hints in the SQL query to ensure a better plan is used.
The RonDB team isn't satisfied with this however, we have realised that evaluating aggregation is also very important when the online feature store stores a time window of certain features. This means that RonDB can compute aggregate dynamically and thus provide more accurate predictions.
Early tests of some simple single table queries showed an improvement of 4-5x and we expect we will be able to get to 10-20x improvements in quite a few queries of this sort.