Release of RonDB 21.04.0
RonDB is based on MySQL NDB Cluster optimised for use in modern cloud settings. Today we launch RonDB 21.04.0. In RonDB 21.04.0 we have integrated benchmark scripts to execute various benchmarks towards RonDB.
There are three ways of using RonDB. The first is using the managed version provided by Logical Clocks. This is currently available in AWS and is currently being developed to also support Azure. This is still in limited access mode. To access it contact Logical Clocks at the rondb.com website.
The second way is to use a script provided by Logical Clocks that automates the creation of VMs and the installation of the software components required by RonDB. These scripts are available to create RonDB clusters on Azure and GCP (Google Cloud). This script can be downloaded from nexus.hops.works/rondb-cloud-installer.sh.
The third manner to use RonDB is to simply download the RonDB binary tarball and install it on any computers of your own liking.
All these methods start by visiting http://rondb.com. From here you will find the download scripts, the tarball to download and to send an email request access to the managed version of RonDB.
RonDB 21.04.0 can be used in any of the above settings, but we focus our development, testing and optimisations towards executing RonDB in an efficient manner in AWS, Azure and GCP. We will likely add Oracle Cloud eventually to the mix as well.
Benchmark Setup
What we have discovered in our benchmarking is that even with very similar HW there are some differences in how RonDB performs on the different clouds. So this report presents the results using very similar setups in AWS, Azure and GCP.
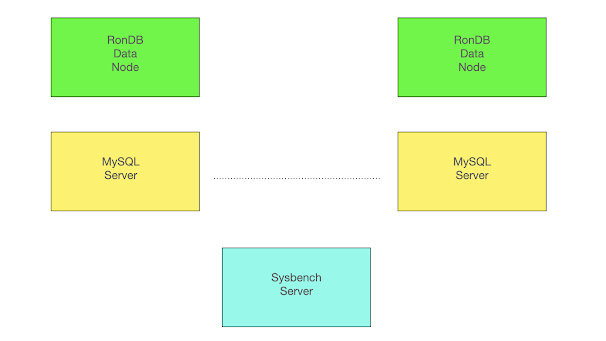
Above we have the benchmark setup used in all the experiments. There are always 2 RonDB data nodes and they are replicas of each other. Thus all write operations are written on both data nodes to ensure that we are always available even in the presence of node failures.
The MySQL Servers are pure clients since data is located on the RonDB data nodes. Thus we can easily scale the benchmark using any number of MySQL Servers. The benchmark application runs on a single VM that sends SQL queries to the MySQL Servers and receives results using a MySQL client written in C. It is sufficient to have a single Sysbench server for these experiments.
In this experiment we will scale RonDB data nodes by using different VM types. It is also possible to scale RonDB by adding more RonDB data nodes. Both of these changes can be performed without any downtime.
It is possible to execute the Sysbench server local to the MySQL Server and let multiple Sysbench servers execute in parallel. This would however be a 2-tiered cluster and we wanted to test a 3-tiered cluster setup since we think this is the most common setup used. Obviously a 2-tiered cluster setup will have lower latency, but it will also be more complex to maintain.
There is also a RonDB management server in the setup, however this is not involved in the benchmark execution and is either located in the Sysbench server or a separate dual CPU VM.
Availability Zones
AWS, Azure and GCP all use a concept called Availability Zones. These are located in the same city, but can be distant from each other. The latency between Availability Zones can be more than 1 millisecond in latency for each jump. RonDB contains options to optimise for such a setup, but in this test we wanted to test a setup that is within an Availability Zone.
Thus all setups we ensured that all VMs participating in cluster setup were in the same zone. Even within a zone the variance on the latency can be substantial. We see this in that the benchmark numbers can vary even within the same cloud and the same availability zone on different runs. From other reports it is reported that network latency is around 40-60 microseconds between VMs in the same availability zone. Our experience is that it is normal that this latency varies at least 10-20 microseconds up or down. In Azure it is even possible that the variance is higher since they can implement some availability zones in multiple buildings. In this case Azure provides a concept called Proximity Placement Groups that can be used to ensure that VMs are located in the same building and not spread between buildings in the same availability zone.
RonDB VM Types
All cloud vendors have VMs that come from different generations of SW and HW. For a latency sensitive application like RonDB this had serious implications. All the VMs we tested used very similar Intel x86 CPUs. There is some difference in performance between older Intel x86 and newer CPUs. However this difference is usually on the order of 30-40%, so not so drastic.
However an area where innovation has happened at a much higher pace is networking. Cloud vendors have drastically improved the networking latency, bandwidth and efficiency from generation to generation.
What we found is that it is essential to use the latest VM generation for MySQL Servers and RonDB data nodes. The difference between the latest generation and the previous generation was up to 3x in latency and performance. We found that the latest generation of VMs from all cloud vendors have similar performance, but using older versions had a high impact on the benchmark results. All the benchmarking results in this report uses the latest generation of VMs from all vendors.
For AWS this means using their 5th generation VMs. AWS has three main categories of VMs, these c5, m5 and r5. c5 VMs are focused on lots of CPU and modest amounts of memory. m5 VMs twice as much memory with the same amount of CPU and r5 have 4x more memory than the c5 and the same amount of CPU. For RonDB this works perfectly fine. The RonDB data nodes store all the data and thus require as much memory as possible. Thus we use the r5 category here. MySQL Servers only act as clients in RonDB setup, thus require only a modest amount of memory, thus we use the c5 category here.
The latest generation in Azure is the v4 generation. Azure VMs have two categories, the D and E VMs. The E category has twice as much memory as the D category. The E category is similar to AWS r5 and the D category is similar to the AWS m5 category.
The latest generation in GCP is the n2 generation. They have n2-highcpu that matches AWS c5, n2-standard that matches AWS m5 and n2-highmem that matches AWS r5. GCP also has the ability to extend memory beyond 8 GB per CPU which is obviously interesting for RonDB.
Benchmark Notes on Cloud Vendors
Since we developed the RonDB managed version on AWS we have a bit more experience from benchmarking here. We quickly discovered that the standard Sysbench OLTP RW benchmark actually is not only a CPU benchmark. It is very much a networking benchmark as well. In some benchmarks using 32 VCPUs on the data nodes, we had to send around 20 Gb/sec from the data node VMs. Not all VM types could handle this. In AWS this meant that we had to use a category called r5n. This category uses servers that have 100G Ethernet instead of 25G Ethernet and thus a 32 VCPU VM was provided with bandwidth up to 25G. We didn’t investigate this thoroughly on Azure and GCP.
Some quirks we noted was that the supply of Azure v4 VM instances was somewhat limited. In some regions it was difficult to succeed in allocating a set of large v4 VM instances. In GCP we had issues with our quotas and got a denial to increase the quota size for n2 VMs, which was a bit surprising. This meant that we executed not as many configurations on Azure and GCP. Thus some comparisons are between Azure and AWS only.
Using the latest VM generation AWS, Azure and GCP all had reasonable performance. There were differences of course, but between 10-30% except in one benchmark. Our conclusion is that AWS, Azure and GCP have used different strategies in how to handle networking interrupts. AWS reports the lowest latency on networking in our tests and this is also seen in other benchmark reports. However GCP shows both in our benchmarks and other similar reports to have higher throughput but worse latency. Azure falls in between those.
Our conclusion is that it is likely caused by how network interrupts are handled. If the network interrupts are acted upon immediately one gets the best possible latency. But at high loads the performance goes down since interrupt handling costs lots of CPU. If network interrupts are instead handled using polling the latency is worse, but at high loads the cost of interrupts stays low even at extreme loads.
Thus best latency is achieved through handling interrupts directly and using polling one gets better performance the longer the delay in the network interrupt. Obviously the true answer is a lot more complex than this, but suffice it to say that the cloud vendors have selected different optimisation strategies that work well in different situations.
Benchmark Notes on RonDB
One more thing that affects latency of RonDB to a great extent is the wakeup latency of threads. Based on benchmarks I did while at Oracle I concluded that wakeup latency is about 2x higher on VMs compared to on bare metal. On VMs it can be as high as 25 microseconds, but is likely nowadays to be more like on the order of 10-15 microseconds.
RonDB implements adaptive CPU spinning. This ensures that latency is decreasing when the load increases. This means that we get a latency curve that starts a bit higher, then goes down until the queueing for CPU resources starts to impact latency and after that it follows a normal latency where latency increases as load increases.
Latency variations are very small up to about 50% of the maximum load on RonDB.
In our benchmarks we have measured the latency that 95% of the transactions were below. Thus we didn’t focus so much on single outliers. RonDB is implementing soft real-time, thus it isn’t intended for hard real-time applications where life depends on individual transactions completing in time.
The benchmarks do however report a maximum latency. Most of the time these maximum latencies were as expected. But one outlier we saw, this was on GCP where we saw transaction latency at a bit above 200 ms when executing benchmarks with up to 8 threads. These outliers disappeared when going towards higher thread counts. Thus it seems that GCP VMs have some sort of deep sleep that keeps them down for 200 ms. This latency was always in the range 200-210 milliseconds. Thus it seemed that there was a sleep of 200ms somewhere in the VM. In some experiments on Azure we saw even higher maximum latency with similar behaviour as on GCP. So it is likely that most cloud vendors (probably all) can go into deep sleeps that highly affect latency when operations start up again.
Benchmark Configuration
Ok, now on to numbers. We will show results from 4 different setups. All setups use 2 data nodes. The first setup uses 2 MySQL Servers and both RonDB data nodes and MySQL Servers use VMs with 16 VCPUs. This setup mainly tests latency and performance of MySQL Servers in an environment where data nodes are not overloaded. This test compares AWS, Azure and GCP.
The second setup increases the number of MySQL Servers to 4 in the same setup. This makes the data node the bottleneck in the benchmark. This benchmark also compares AWS, Azure and GCP.
The third setup uses 16 VPUs on data nodes and 2 MySQL Servers using 32 VCPUs. This test shows performance in a balanced setup where both data nodes and MySQL Servers are close to their limit. This test compares AWS and Azure.
The final setup compares a setup with 32 VCPUs on data nodes and 3 MySQL Servers using 32 VCPUs. This setup mainly focuses on behaviour latency and throughput of MySQL Servers in an environment where the data nodes are not the bottleneck. The test compares AWS with Azure.
We used 3 different benchmarks. Standard Sysbench OLTP RW, this benchmark is both a test of CPU performance as well as networking performance. Next benchmark is the same as OLTP RW using a filter where the scans only return 1 of the 100 scanned rows instead of all of them. This makes the benchmark more CPU focused.
The final benchmark is a key lookup benchmark that only sends SQL queries using IN statements. This means that each SQL query performs 100 key lookups. This benchmark shows the performance of simple key lookups using RonDB through SQL queries.
Conclusions
The results show clearly that AWS has the best latency numbers at low to modest loads. At high loads GCP gives the best results. Azure has similar latency to GCP, but doesn’t provide the same benefits at higher loads. These results are in line with similar benchmark reports comparing AWS, Azure and GCP.
The variations from one benchmark run to another run can be significant when it comes to latency. This is natural since there is a random latency added dependent on how far apart the VMs are within the availability zone. However throughput is usually not affected in the same manner.
In some regions Azure uses several buildings to implement one availability zone, this will affect latency and throughput negatively. In those regions it is important to use Proximity Placement Groups in Azure to ensure that all VMs are located in the same building. The effect of this is seen in the last benchmark results in this report.
The limitations on VM networking are a bit different. This played out as a major factor in the key lookup benchmark where one could see that AWS performance was limited due to network bandwidth limitation. Azure VMs had access to a higher networking bandwidth for similar VM types.
AWS provided the r5n VM types, this provided 4x more networking bandwidth with the same CPU and memory setup. This provided very useful for benchmarking using RonDB data nodes with 32 VCPUs.
Benchmark Results
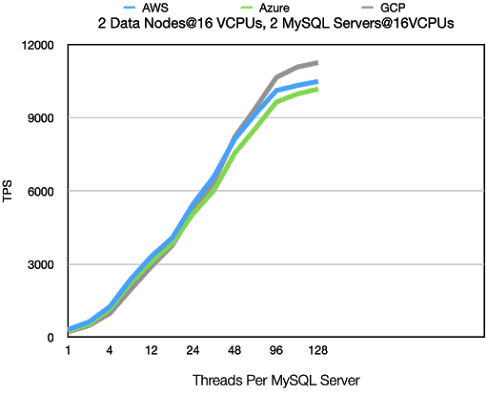
2 Data Nodes@16 VCPUs, 2 MySQL Server@16 VCPUs
Standard OLTP RW
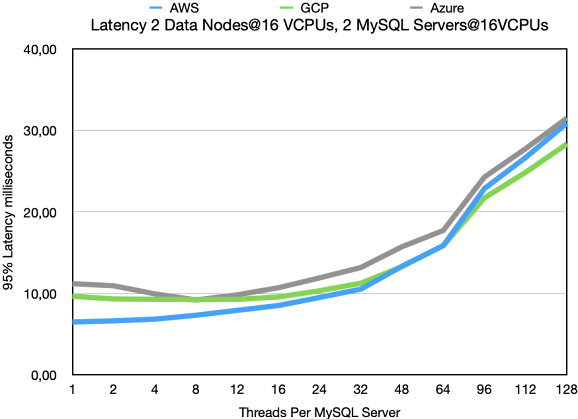
In this benchmark we see clearly the distinguishing features of AWS vs GCP. AWS
has better latency at low load. 6,5 milliseconds compared to 9,66 milliseconds.
However GCP reaches higher performance. At 128 threads it reaches 7% higher
performance at 7% lower latency. So GCP focuses on the performance at high load
whereas AWS focuses more on performance at lower loads. Both approaches have
obvious benefits, which is best is obviously subjective and depends on the application.
This benchmark is mainly testing the throughput of MySQL Servers. The RonDB
data nodes are only loaded to about 60-70% of their potential throughput with
2 MySQL Servers.
Moving to latency numbers one can see the same story, but even clearer. AWS has
a better latency up to 48 threads where the latency of GCP becomes better. In GCP
we see that the latency at 1 thread is higher than the latency at 12 threads and only
at 24 threads the latency starts to increase beyond the latency at 1 thread. Thus in
GCP the latency is very stable over different loads until the load goes beyond 50%
of the possible throughput. We see the same behaviour on Azure whereas AWS
latency slowly starts to increase at lower thread counts.
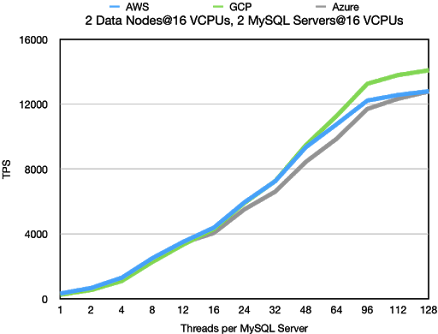
Standard OLTP RW using filter
The OLTP RW using a filter is more focused on CPU performance. The major difference
is seen at higher loads. The latency at low loads is very similar, but at higher loads we
get higher throughput at lower latency. Thus standard OLTP RW has a steeper march
from acceptable latency to high latency. The difference in throughput is very small
between cloud vendors, it is within 10%.
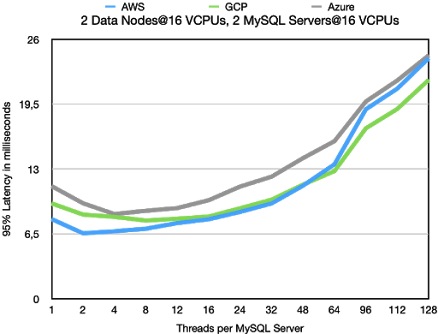
The comparison between AWS and GCP is similar though. The GCP benefit at higher
load is slightly higher and similar to the latency. The AWS advantage at lower loads is
slightly lower. Thus GCP has a slight advantage compared to standard OLTP RW,
but it is a very small difference.
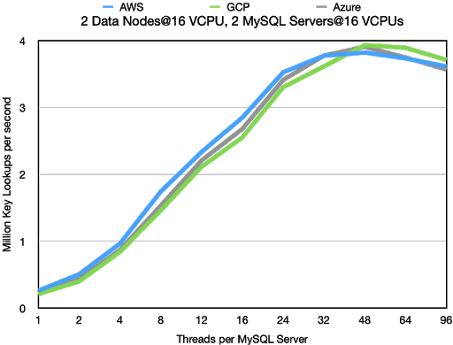
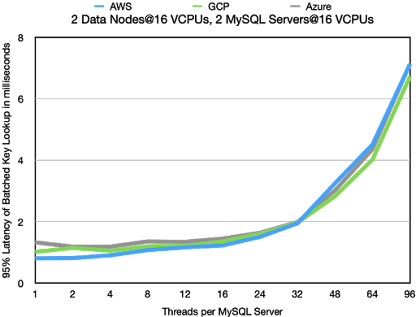
Key Lookups
In the graph below we see the number of key lookups that 2 MySQL Servers can drive.
The numbers are very equal for the different cloud vendors. AWS as usual has an
advantage at lower thread counts and GCP gains the higher numbers at higher
thread counts and Azure is usually in the middle.
The latency numbers are shown below. These numbers more clearly show the
advantage of AWS at lower thread counts. At higher thread counts the latency
is mostly the same for all cloud vendors. This benchmark is extremely regular
in its use case and thus it is mostly the CPU performance that matters in this
benchmark. Since this is more or the less same on all cloud vendors we see
no major difference.
2 Data Nodes@16 VCPUs, 4 MySQL Server@16 VCPUs
In this benchmark the bottleneck moves to the RonDB data nodes. We now have
sufficient amounts of MySQL Servers to make the RonDB data nodes a bottleneck.
This means a bottleneck that can be both a CPU bottleneck as well as a networking
bottleneck.
Standard OLTP RW
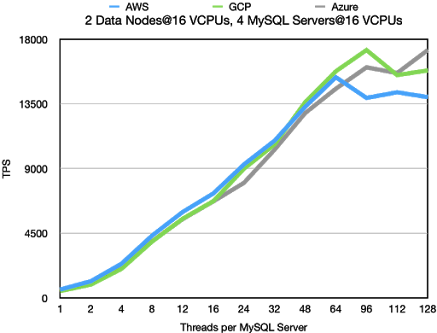
The latency is very stable until we reach 64 threads where we have around 15k TPS at
20 milliseconds latency. At higher thread counts the data nodes becomes the bottleneck
and in this case the latency has a much higher variation. We can even see that latency
at 128 threads in Azure goes down and throughput up. We expect that this is due to
interrupt handling being executed on the same CPUs as database processing happens.
This is something that we will look more into.
OLTP RW using filter
The throughput of OLTP with a filter means that the focus is more on CPU performance.
This makes it clear that the high variation on throughput and latency in standard OLTP RW
comes from handling the gigabytes per second of data to send to the MySQL Servers.
In this benchmark the throughput increases in a stable manner and similarly the latency
goes up in an expected manner.
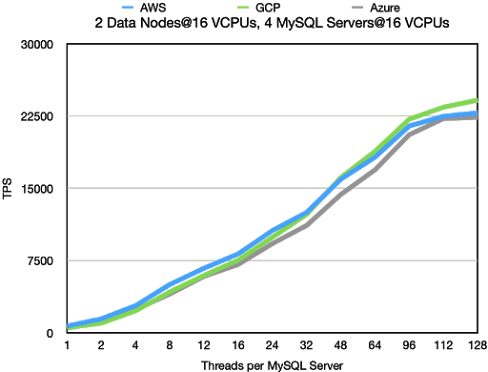
All cloud vendors are very close to each other except at low thread counts where
AWS have an advantage.
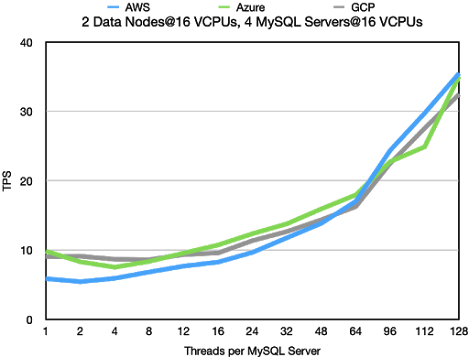
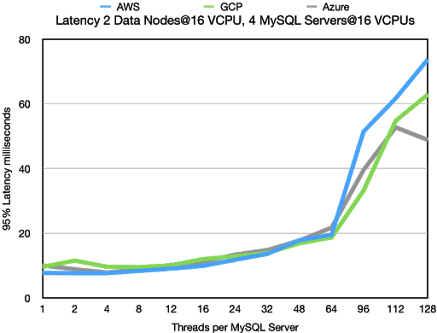
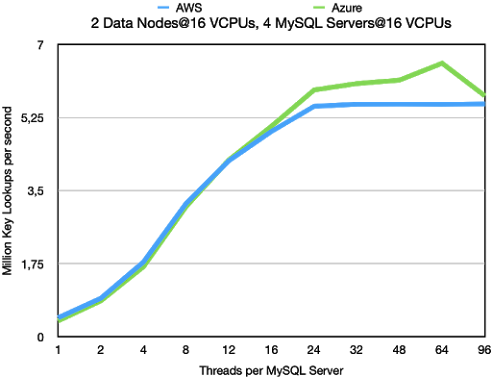
Key Lookups
The key lookups with 4 MySQL Server and 2 data nodes and all nodes using
16 VCPUs per node moves the bottleneck to the data node. As usual AWS
wins out on the latency at lower thread counts. But at higher thread counts
AWS hits a firm wall. Most likely it hits a firm bandwidth limitation on the VMs.
This limitation is higher on Azure, thus these VM can go an extra mile and serve
1 million more key lookups per second.
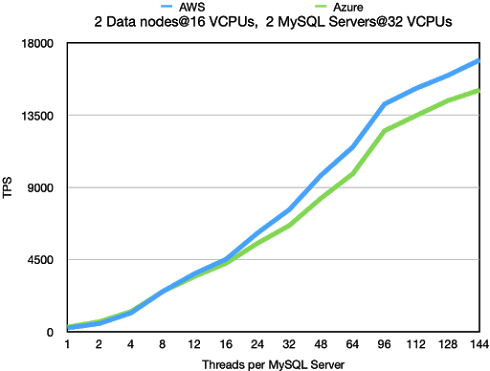
2 Data Nodes@16 VCPUs, 2 MySQL Server@32 VCPUs
This benchmark uses the same amount of CPUs on the MySQL Server side,
but instead of divided on 4 MySQL Servers, it is using 2 MySQL Servers.
We didn’t test GCP in this configuration. We expect no surprises in throughput
and latency if we do.
Standard OLTP RW
In the Standard OLTP RW we see that the throughput is the same as with
4 MySQL Servers. However the throughput increases in a more regular manner.
What we mainly see is that we can achieve a higher throughput using a smaller
amount of threads in total. This makes the throughput more stable. Thus we
conclude that at least up to 32 VCPUs it pays off to use larger MySQL Servers
if required.
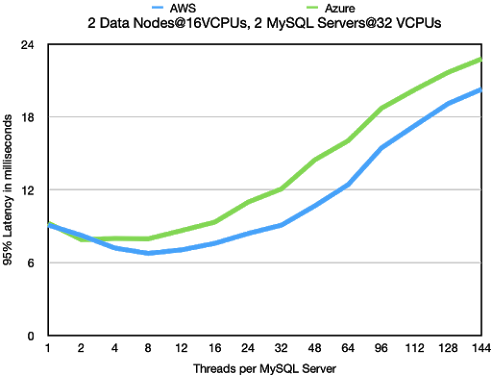
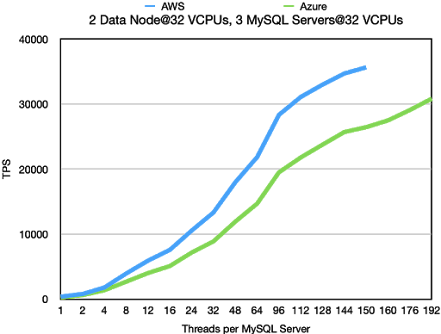
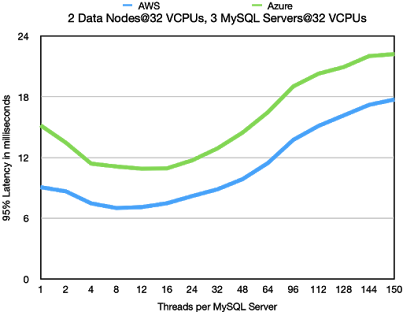
2 Data Nodes@32 VCPUs, 3 MySQL Server@32 VCPUs
In this benchmark we increased the number of CPUs on the RonDB data
nodes to 32 VCPUs. Most of the testing in this setup has been performed
on AWS. The main reason for including the Azure numbers is because
these numbers show the impact of not using Proximity Placement Groups
in Azure on large regions. We saw clearly in these benchmarks that the
latency in the Azure setup was much higher than in previous benchmarks
that were using a smaller region.
However in the smaller region it was difficult to allocate these larger VMs
in any larger number. We constantly got failures due to lacking resources
to fulfil our requests.
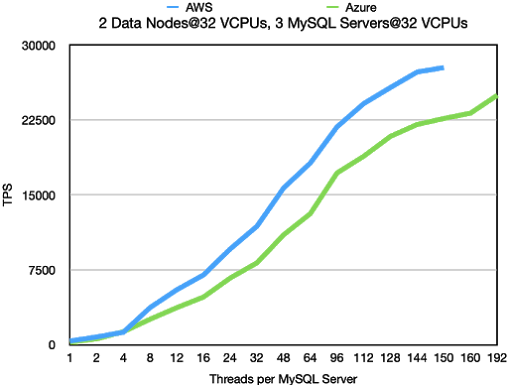
Standard OLTP RW
In AWS we discovered that the network was a bottleneck when executing
this benchmark. Thus we used r5n.8xlarge instead of r5.8xlarge VMs in
this benchmark. These VMs reside in machines with 100G Ethernet
connections and each 32 VCPU VM have access to at least 25 Gb/sec
networking. The setup tested here with 3 MySQL Servers doesn’t load the
RonDB data node fully. In other benchmarks we were able to increase
throughput to around 35k TPS. However these benchmarks used a different
setup, so these numbers are not relevant for a comparison. What we see is
that the throughput in this case is roughly twice the throughput when using
16 VCPUs in the data nodes.
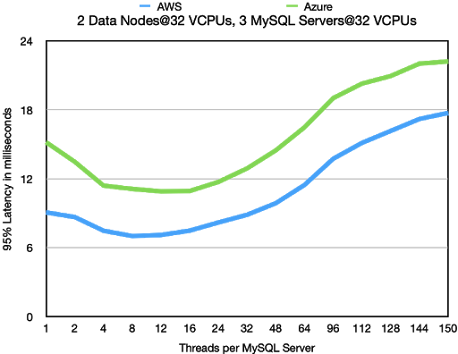
Latency numbers look very good and it is clear that we haven't really
reached the bottleneck really in neither the MySQL Servers nor the
RonDB data nodes.
OLTP RW using filter
Similarly in this experiment we haven’t really reached the bottleneck on neither the
RonDB data nodes nor the MySQL Servers. So no real news from this benchmark.