Introduction
Sysbench is a tool to benchmark to test open source databases. We have integrated Sysbench into the RonDB installation. This makes it extremely easy to run benchmarks with RonDB. This paper will describe the use of these benchmarks in RonDB. These benchmarks were executed with 1 cluster connection per MySQL Server. This limited the scalability per MySQL Server to about 12 VCPUs. Since we executed those benchmarks we have increased the number of cluster connections per MySQL Server to 4 providing scalability to at least 32 VCPUs per MySQL Server.
As preparation to run those benchmarks we have created a RonDB cluster using the Hopsworks framework that is currently used to create RonDB clusters. In these tests all MySQL Servers are using the c5.4xlarge VM instances in AWS (16 VCPUs with 32 GB memory). We have a RonDB management server using the t3a.medium VM instance type. We have tested using two different RonDB clusters, both have 2 data nodes. The first test is using the r5.4xlarge instance type (16 VCPUs and 128 GB memory) and the second test uses the r5n.8xlarge (32 VCPUs and 256 GB memory). It was necessary to use r5n class since we needed more than 10Gbit/second network bandwidth for the OLTP RW test with 32 VCPUs on data nodes.
In the RonDB documentation you can find more details how to set up your own RonDB cluster in either our managed version (currently supporting AWS) or using our open source shell scripts to set up a cluster (currently supporting GCP and Azure). RonDB is a new distribution of MySQL NDB Cluster. All experiments in this blog was performed using RonDB 21.04.0.
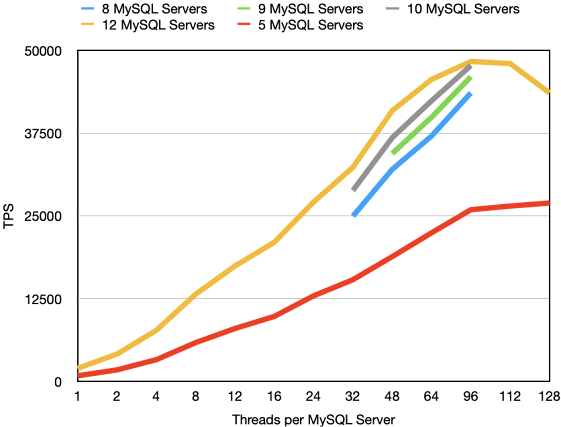
The graph below shows the throughput results from the larger data nodes using 8-12 MySQL Server VMs. Now in order to make sense of these numbers we will explain a bit more about Sysbench and how you can tweak Sysbench to serve your purposes for testing RonDB.
Description of Sysbench OLTP RW
The Sysbench OLTP RW benchmark consists of 20 SQL queries. There is a transaction, this means that the transaction starts with a BEGIN statement and it ends with a COMMIT statement. After the BEGIN statement follows 10 SELECT statements that selects one row using the primary key of the table. Next follows 4 SELECT queries that select 100 rows within a range and either uses SELECT DISTINCT, SELECT … ORDER BY, SELECT or SELECT sum(..). Finally there is one INSERT, one DELETE and 2 UPDATE queries.
In Pseudo code thus:
BEGIN
Repeat 10 times: SELECT col(s) from TAB where PK=pk
SELECT col(s) from TAB where key >= start AND key < (start + 100)
SELECT DISTINCT col(s) from TAB where key >= start AND key < (start + 100)
SELECT col(s) from TAB where key >= start AND key < (start + 100) ORDER BY key
SELECT SUM(col) from TAB where key >= start AND key < (start + 100)
INSERT INTO TAB values (....)
UPDATE TAB SET col=val WHERE PK=pk
UPDATE TAB SET col=val WHERE key=key
DELETE FROM TAB WHERE PK=pk
COMMIT
This is the standard OLTP RW benchmark.
Benchmark Execution
Now I will describe some changes that the Sysbench installation in RonDB can handle. To understand this we will start by showing the default configuration file for Sysbench.
#
# Software definition
#
MYSQL_BIN_INSTALL_DIR="/srv/hops/mysql"
BENCHMARK_TO_RUN="sysbench"
#
# Storage definition (empty here)
#
#
# MySQL Server definition
#
SERVER_HOST="172.31.23.248;172.31.31.222"
MYSQL_PASSWORD='3*=13*8@20.*0@7$?=45'
#
# NDB node definitions (empty here)
#
#
# Benchmark definition
#
SYSBENCH_TEST="oltp_rw"
SYSBENCH_INSTANCES="2"
THREAD_COUNTS_TO_RUN="1;2;4;8;12;16;24;32;48;64;96;112;128"
MAX_TIME="30"
In this configuration file we provide the pointer to the RonDB binaries, we provide the type of benchmark we want to execute, we provide the password to the MySQL Servers, we provide the number of threads to execute in each step of the benchmark. There is also a list of IP addresses to the MySQL Servers in the cluster and finally we provide the number of instances of Sysbench we want to execute.
This configuration file is created automatically by the managed version of RonDB. This configuration file is available in the API nodes you created when you created the cluster. They are also available in the MySQL Server VMs if you want to test running with a single MySQL Server colocated with the application.
The default setup will run the standard Sysbench OLTP RW benchmark with one sysbench instance per MySQL Server. To execute this benchmark the following steps are done:
Step 1: Log in to the API node VM where you want to run the benchmark from. The username is ubuntu (in AWS). Thus log in using e.g. ssh ubuntu@IP_address. The IP address is the external IP address that you will find in AWS where your VM instances are listed.
Step 2: After successfully being logged in you need to log into the mysql user using the command:
sudo su - mysql
Step 3: Move to the right directory
cd benchmarks
Step 4: Execute the benchmark
bench_run.sh --default-directory /home/mysql/benchmarks/sysbench_multi
Benchmark Results
As you will discover there is also a sysbench_single, dbt2_single, dbt2_multi directory. These are setup for different benchmarks that we will describe in future papers. sysbench_single is the same as sysbench_multi but with only a single MySQL Server. This will exist also on MySQL Server VMs if you want to benchmark from those. Executing a benchmark from the sysbench machine increases latency since it represents a 3-tiered setup whereas executing sysbench in the MySQL Server represents a 2-tiered setup and thus the latency is lower.
If you want to study the benchmark in real-time repeat Step 1, 2 and 3 above and then perform the following commands:
cd sysbench_multi/sysbench_results
tail -f oltp_rw_0_0.res
This will display the output from the first sysbench instance that will provide latency numbers and throughput of one of the sysbench instances.
When the benchmark has completed the total throughput is found in the file:
/home/mysql/benchmarks/sysbench_multi/final_results.txt
Modifying Sysbench benchmark
The configuration for sysbench_multi is found in:
/home/mysql/benchmarks/sysbench_multi/autobench.conf
Thus if you want to modify the benchmark you can edit this file.
So how can we modify this benchmark. First you can decide on how many SELECT statements to retrieve using the primary key that should be issued. The default is 10. To change this add the following line in autobench.conf:
SB_POINT_SELECTS=”5”
This will change such that instead 5 primary key SELECTs will be issued for each transaction.
Next you can decide that you want those primary key SELECTs to retrieve a batch of primary keys. In this case the SELECT will use IN (key1, key2,,, keyN) in the WHERE clause. To use this set the number of keys to retrieve per statement in SB_USE_IN_STATEMENT. Thus to set this to 100 add the following line to autobench.conf.
SB_USE_IN_STATEMENT=”100”
This means that if SB_POINT_SELECTS is set to 5 and SB_USE_IN_STATEMENT is set to 100 there will be 500 key lookups performed per Sysbench OLTP transaction.
Next it is possible to set the number of range scan SELECTs to perform per transaction. So to e.g. disable all range scans we can add the following lines to autobench.conf.
SB_SIMPLE_RANGES=”0”
SB_ORDER_RANGES=”0”
SB_DISTINCT_RANGES=”0”
SB_SUM_RANGES=”0”
Now it is also possible to modify the range scans. I mentioned that the range scans retrieves 100 rows. The number 100 is changeable through the configuration parameter SB_RANGE_SIZE.
The default behaviour is to retrieve all 100 rows and send them back to the application. Thus no filtering. We also have an option to perform filtering in those range scans. In this case only 1 row will be returned, but we will still scan the number of rows specified in SB_RANGE_SIZE. This feature of Sysbench is activated through adding the following line to autobench.conf:
SB_USE_FILTER=”yes”
Finally it is possible to remove the use of INSERT, DELETE and UPDATEs. This is done by changing the configuration parameter SYSBENCH_TEST from oltp_rw to oltp_ro.
There are many more ways to change the configuration of how to run Sysbench, but these settings are enough for this paper. For more details see the documentation of dbt2-0.37.50, also see the Sysbench tree
Benchmark Configurations
In my benchmarking reported in this paper I used 2 different configurations. Later we will report more variants of Sysbench testing as well as other benchmark variants.
The first is the standard Sysbench OLTP RW configuration. The second is the standard benchmark but adding SB_USE_FILTER=”yes”. This was added since the standard benchmark becomes limited by the network bandwidth using r5.8xlarge instances for the data node. This instance type is limited to 10G Ethernet and it needs almost 20 Gb/s in networking capacity with the performance that RonDB delivers. This bandwidth is achievable using the r5n instances.
Each test of Sysbench creates the tables and fills them with data. To have a reasonable execution time of the benchmark each table will be filled with 1M rows. Each sysbench instance will use its own table. It is possible to set the number of rows per table, it is also possible to use multiple tables per sysbench instance. Here we have used the default settings.
The test runs are executed for a fairly short time to be able to test a large variety of test cases. This means that it is expected that results are a bit better than expected. To see how results are affected by running for a long time we also ran a few select tests where we ran a single benchmark for more than 1 hour. The results are in this case around 10% lower than the numbers of shorter runs. This is mainly due to variance of the throughput that is introduced by the execution of checkpoints in RonDB. Checkpoints consume around 5-10% of the CPU capacity in the RonDB data nodes.
Benchmark setup
In all tests set up here we have started the RonDB cluster using the Hopsworks infrastructure. In all tests we have used c5.4xlarge as the VM instance type for MySQL Servers. This VM has 16 VCPUs and 32 GB of memory. This means a VM with more or less 8 Intel Xeon CPU cores. In all tests there are 2 RonDB data nodes, we have tested with 2 types of VM instances here, the first is the r5.4xlarge which has 16 VCPUs with 128 GB of memory. The second is the r5n.8xlarge which has 32 VCPUs and 256 GB of memory. In the Standard Sysbench OLTP RW test the network became a bottleneck when using r5.8xlarge. These VMs can use up to 10 Gb/sec, but in reality we could see that some instances could not go beyond 7 Gb/sec, when switching to r5n.8xlarge instead this jumped up to 13Gb/sec immediately, so clearly this bottleneck was due to the AWS infrastructure.
To ensure that the network bottleneck was removed we switched to using r5n.8xlarge instances instead for those benchmarks. These instances are the same as r5.8xlarge except that they can use up to 25 Gb/sec in network bandwidth instead of 10Gb/sec.
Standard Sysbench OLTP RW
The first test we present here is the standard OLTP RW benchmark. When we run this benchmark most of the CPU consumption happens in the MySQL Servers. Each MySQL Server is capable of processing about 4000 TPS for this benchmark. The MySQL Server can process a bit more if the responsiveness of the data node is better, this is likely to be caused by that the CPU caches are hotter in that case when the response comes back to the MySQL Server. Two 16 VCPU data nodes can in this case handle the load from 4 MySQL Servers, adding a 5th can increase the performance slightly, but not much. We compared this to 2 data nodes using 32 VCPUs and in principle the load these data nodes could handle was doubled.
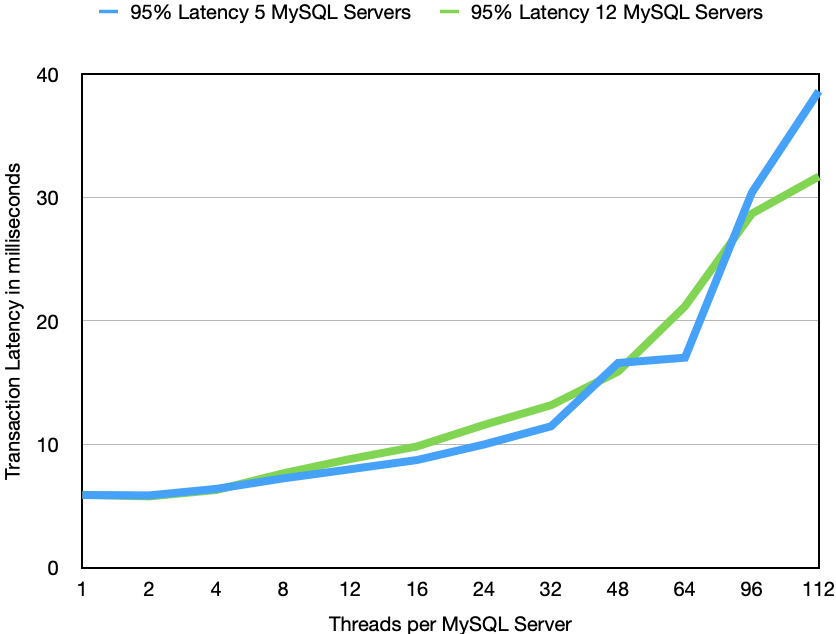
The response time was very similar in both cases, at extreme loads the larger data nodes had more latency increases, most likely due to the fact that we got much closer to the limits of what the network could handle.
The top number here was 34870 at 64 threads from 10 MySQL Servers. In this case 95% of the transactions had a latency that was less than 19.7 ms, this means that the time for each SQL query was below 1 millisecond. This meant that almost 700k SQL queries per second were executed. These queries reported back to the application 14.5M rows per second for the larger data nodes, most of them coming from the 4 range scan queries in the benchmark. Each of those rows are a bit larger than 100 bytes, thus around 2 GByte per second of application data is transferred to the application (about 25% of this is aggregated in the MySQL when using the SUM range scan).
Sysbench OLTP RW with filtering of scans
Given that Sysbench OLTP RW is to a great extent a networking test we also wanted to perform a test that performed a bit more processing, but reporting back a smaller amount of rows. We achieved this by setting SB_USE_FILTER=”yes” in the benchmark configuration file. This means that instead of each range scan SELECT reporting back 100 rows, it will read 100 rows and filter out 99 of them and report only 1 of the 100 rows. This will decrease the amount of rows to process down to about 1M rows per second. Thus this test is a better evaluator of the CPU efficiency of RonDB whereas the standard Sysbench OLTP RW is a good evaluator of RonDBs ability to ship tons of rows between the application and the database engine.
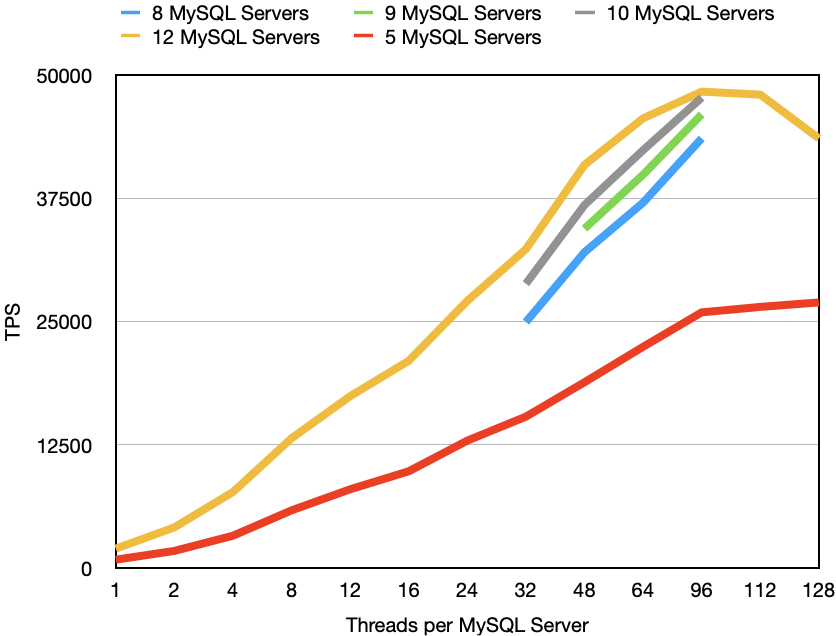
At first we wanted to see the effect the number of MySQL servers had on the throughput in this benchmark. We see the results of this in the image above. We see that there is an increase in throughput going from 8 to 12 MySQL Servers. However the additional effect of each added MySQL Server is diminishing. There is very little to gain going beyond 10 MySQL Servers. The optimal use of computing resources is most likely achieved around 8-9 MySQL Servers.
Adding additional MySQL servers also has an impact on the variability of the latency. So probably the overall best fit here is to use about 2x more CPU resources on the MySQL Servers compared to the CPU resources in the RonDB data nodes. This rule is based on this benchmark and isn’t necessarily true for another use case.
The results with the smaller data nodes, r5.4xlarge is the red line that used 5 MySQL Servers in the test.
The rule definitely changes when using the key-value store APIs that RonDB provides. These are at least 100% more efficient compared to using SQL.
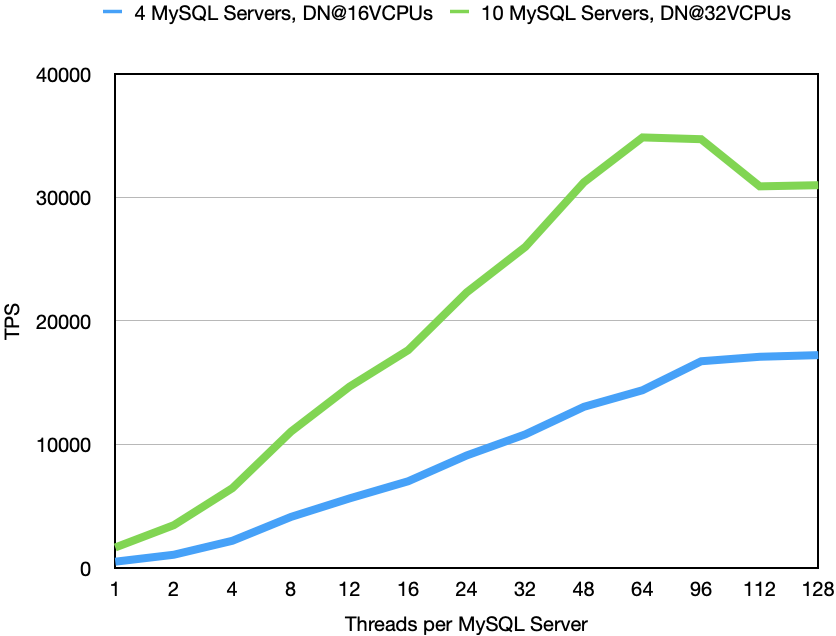
A key-value store needs to be a LATS database (low Latency, high Availability, high Throughput, Scalable storage). In this paper we have focused on showing Throughput and Latency. Above is the graph showing how latency is affected by the number of threads in the MySQL Server.
Many applications have strict requirements on the maximum latency of transactions. So for example if the application requires response time to be smaller than 20 ms than we can see in the graph that we can use around 60 threads towards each MySQL Server. At this number of threads r5.4xlarge delivers 22500 TPS (450k QPS) and r5n.8xlarge delivers twice that number, 45000 TPS (900k QPS).
The base latency in an unloaded cluster is a bit below 6 milliseconds. This number is a bit variable based on where exactly the VMs are located that gets started for you. Most of this latency is spent in latency on the networks. Each network jump in AWS has been reported to be around 40-50 microseconds and one transaction performs around 100 of those network jumps in sequence. Thus almost two-thirds of the base latency comes from the latency in getting messages across. At higher loads the queueing waiting the message to be executed becomes dominating. Benchmarks where everything executes on a single computer has base latency around 2 millisecond per Sysbench transaction which confirms the above calculations.
No comments:
Post a Comment