This blog introduces how RonDB handles automatic thread configuration. This blog is more technical and dives deeper under the surface of how RonDB operates. RonDB provides a configuration option, ThreadConfig, whereby the user can have full control over the assignment of threads to CPUs, how the CPU locking is to be performed and how the thread should be scheduled.
However for the absolute majority of users this is too advanced, thus the managed version of RonDB ensures that this thread configuration is based on best practices found over decades of testing. This means that every user of the managed version of RonDB will get access to a thread configuration that is optimised for their particular VM size.
In addition RonDB makes use of adaptive CPU spinning in a way that limits the power usage, but still provides very low latency in all database operations. This improves latency by up to 50% and in most cases more than 10% improvement.
RonDB 21.04 uses automatic thread configuration by default. This means that as a user you don’t have to care about the configuration of threads. What RonDB does is that it retrieves the number of CPUs available to the RonDB data node process. In the managed version of RonDB, this is the full VM or bare metal server available to the data node. In the open source version of RonDB one can also limit the amount of CPUs available to RonDB data nodes process by using taskset or numactl when starting the data node. RonDB retrieves information about CPU cores, CPU sockets and connections to the L3 caches of the CPUs. All of this information is used to set up the optimal thread configuration.
Thread types in RonDB

LDM threads that house the data, query threads that handles read committed queries, tc threads that handles transaction coordination, receive threads that handles receive of network messages, send threads that handles sending of network messages, and main threads that handle metadata operations, asynchronous replication and a number of other things.
LDM threads
LDM thread is a key thread type. The LDM thread is responsible to read and write data. It manages the hash indexes, the ordered indexes, the actual data and a set of triggers performing actions for indexes, foreign keys, full replication, asynchronous replication. This thread type is where most of the CPU processing is done. RonDB has an extremely high number of instructions per cycle compared to any other DBMS engine. The LDM thread often executes 1.25 instructions per cycle where many other DBMS engines have reported numbers around 0.25 instructions per cycle. This is a key reason why RonDB has such a great performance both in terms of throughput and latency. This is the result of a design of data structures in RonDB that is CPU cache aware and the functional separation of thread types.
Query threads
Query thread makes it possible to decrease the amount of partitions in a table. As an example we are able to process more than 3 times as many transactions per second using a single partition in Sysbench OLTP RW compared to when we only use LDM threads.
Most key-value stores have data divided into table partitions for the primary key of the table. Many key-value stores also contain additional indexes on columns that are not used for partitioning. Since the table is partitioned, this means that each table partition will contain each of those additional indexes.
When performing a range scan on such an index, each table partition must be scanned. Thus the cost of performing range scans increases as the number of table partitions increases. RonDB can scale the reads in a single partition to many query threads, this makes it possible to decrease the number of table partitions in RonDB. In Sysbench OLTP RW this improves performance by around 20% even in a fairly small 2-node setup of RonDB.
In addition query threads ensure that hotspots in the tables can be handled by many threads, thus avoiding the need to partition even more to handle hotspots.
At the same time a modest amount of table partitions increases the amount of writes that we can perform on a table and it makes it possible to parallelise range scans which will speed up complex query execution significantly. Thus in RonDB we have attempted to find a balance between overhead and improved parallelism and improved write scalability.
Costs of key lookups are not greatly affected by the number of partitions since those use a hash lookup and thus always go directly to the thread that can execute the key lookup.
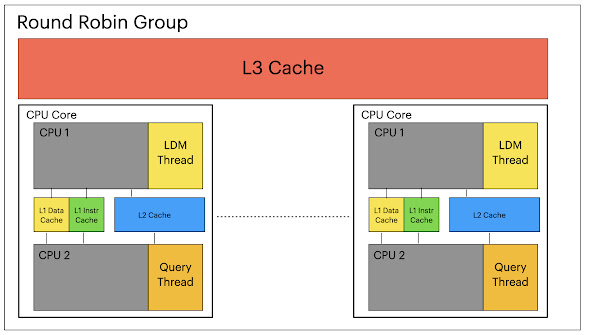
RonDB locks LDM threads and query threads in pairs. There is one LDM thread and one query thread in each such LDM group, we attempt to lock this LDM Group to one CPU core. LDM Groups are organised into Round Robin Groups.
A common choice for a scheduling algorithm in an architecture like this would be to use a simple round robin scheduler. However such an algorithm is too simple for this model. We have two problems to overcome. The first is that the load on LDM threads is not balanced since we have decreased the number of table partitions in a table. Second writes and locked reads can only be scheduled in an LDM thread. Thus it is important to use the Read Committed queries to achieve a balanced load.

Given that we use less table partitions in RonDB compared to other solutions, there is a
risk of imbalanced load on the CPUs. This problem is solved by two things. First we
use a two-level load balancer on LDM and Query threads. This ensures that we will
move away work from overloaded LDM threads towards unused query threads.
Second since the LDM and Query threads share the same CPU core we will make great
progress in query threads that execute on the same CPU core as an LDM thread that is
currently underutilized. Thus we expect that this architecture will achieve a balanced load
on the CPU cores in the data node architecture.
LDM and query threads use around 50-60% of the available CPU resources in a data node.
tc threads
The tc threads receive all database operations sent from the NDB API. It takes care of
coordinating transactions and decides which node should take care of the queries.
It uses around 20-25% of the CPU resources. The NDB API selects tc threads in a node
using a simple round robin scheme.
receive threads
The receive threads take care of a subset of the communication links. Thus the receive
thread load is usually fairly balanced but can be a bit more unbalanced if certain API nodes
are more used in querying RonDB. The communication links between data nodes in the
same node group are heavily used when performing updates. To ensure that RonDB can
scale in this situation these node links use multiple communication links. Receive threads
use around 10-15% of the CPU resources.
send threads
The send threads assist in sending networking messages to other nodes. The sending of
messages can be done by any thread and there is an adaptive algorithm that assigns more
load for sending to threads that are not so busy. The send threads assists in sending to
ensure that we have enough capacity to handle all the load. It is not necessary to have
send threads, the threads can handle sending even without a send thread. Send threads
use around 0-10% of the CPUs available.
The total cost of sending can be quite substantial in a distributed database engine, thus
the adaptive algorithm is import to balance out this load on the various threads in
the data node.
main threads
The main threads can be 0, 1 or 2. These threads handle a lot of the interactions around
creating tables, indexes and any other metadata operation. They also handle a lot of the
code around recovery and heartbeats. They are handling any subscriptions to
asynchronous replication events used by replication channels to other RonDB clusters.
Background
RonDB is based on NDB Cluster. NDB was focused on being a high-availability key-value
store from its origin in database research in the 1990s. The thread model in NDB is
inherited from a telecom system developed in Ericsson called AXE. Interestingly in one of
my first jobs at Philips I worked on a banking system developed in the 1970s, this system
had a very similar model compared to the original thread model in NDB and in AXE. In the
operating system development time-sharing has been the dominant model since a long time
back. However the model used in NDB where the execution thread is programmed as an
asynchronous engine where the application handles a state machine has a huge
performance advantage when handling many very small tasks. A normal task in RonDB
is a key lookup, or a small range scan. Each of those small tasks is actually divided even
further when performing updates and parallel range scans.
This means that the length of a task in RonDB is on the order of 500 ns up to around
10 microseconds.
Traditional thread design for key-value stores
Time-sharing operating systems are not designed to handle context switches of this
magnitude. NDB was designed with this understanding from the very beginning. Early
competitors of NDB used normal operating system threads for each transaction
and even in a real-time operating system this had no chance to compete with the
effectiveness of NDB. None of these competitors are still around competing in the
key-value store market.
Asynchronous thread model
The first thread model in NDB used a single thread to handle everything, send, receive,
database handling and transaction handling. This is version 1 of the thread architecture,
this is implemented also in the open source version of Redis. With the development of
multi-core CPUs it became obvious that more threads were needed. What NDB did
here was introduce both a functional separation of threads and partitioning the data to
achieve a more multi-threaded execution environment. This is version 2 of the thread
architecture.
Modern competitors of RonDB have now understood the need to use asynchronous
programming to achieve the required performance in a key-value store. We see this in
AeroSpike, Redis, ScyllaDB and many other key-value stores. Thus the industry has
followed the RonDB road to achieving an efficient key-value store implementation.
Functional separation of threads
Most competitors have opted for only partitioning the data and thus each thread still
has to execute all the code for meta data handling, replication handling, send, receive and
database operations. Thus RonDB has actually advanced version 2 of the thread
architecture further than its competitors.
One might ask, what difference does this make?
All modern CPUs use both a data cache and an instruction cache. By combining all
functions inside one thread, the instruction cache will have to execute more code.
In RonDB the LDM thread only executes the operation to change the data structures,
the tc thread only executes code to handle transactions and the receive thread can
focus on the code to execute network receive operations. This makes each thread more
efficient. The same is true for the CPU data cache, the LDM thread need not bother with
the data structures used for transaction handling and network receive. It can focus the
CPU caches on the requirements for database operations which is challenging enough
in a database engine.
A scalable key-value store design
A simple splitting of data into different table partitions makes sense if all operations
towards the key-value store are primary key lookups or unique key lookups. However
most key-value stores also require performing general search operations as part of the
application. These search operations are implemented as range scans with search
conditions, these scale not so well with a simple splitting of data.
To handle this RonDB introduces version 3 of the thread architecture that uses a
compromise where we still split the data, but we introduce query threads to assist the
LDM threads in reading the data. Thus RonDB can handle hotspots of data and require
fewer number of table partitions to achieve the required scalability of the key-value store.
Thoughts on a v4 of the thread architecture has already emerged, so expect this
development to continue for a while more. This includes even better handling of
the higher latency to persistent memory data structures.
Finally, even if a competitor managed to replicate all of those features of RonDB,
RonDB has another ace in the 3-level distributed hashing algorithm that makes use of
a CPU cache aware data structure.
All of those things combined makes us comfortable that RonDB will continue to lead
the key-value store market in terms of lowest Latency, highest Availability, the
highest Throughput and the most Scalable data storage. Thus, being
the best LATS database in the industry.
I do not really get function separation of threads. To execute a query, your data will now go through a pipeline of threads, instead of being executed into one. This means, you need to pass data between 4 threads, until the query is finished. It could be achieved via queueing between threads and wakeups , or maybe spinning to avoid more context switches.
ReplyDeleteBut I do not seem to see what's in that trick. My understanding is that, your query will execute the same number, or more CPU instructions, and since now there is a pipeline of several threads, it will suffer either more spinning, or more cache misses, or more context switches due to this tossing data between threads.
ScyllaDB also does something similar with execution stages for better instruction cache https://www.scylladb.com/2017/07/06/scyllas-approach-improve-performance-cpu-bound-workloads/. Is this similar to what you're implementing for instruction cache on separaring the threads ?
ReplyDeleteWrote a reply to those questions in a separate blog entry:
ReplyDeletehttp://mikaelronstrom.blogspot.com/2021/03/designing-thread-pipeline-for-optimal.html