In the previous part we showed how NDB will parallelise a simple
2-way join query from TPC-H. In this part we will describe how
the pushdown of joins to a storage engine works in the MySQL Server.
First a quick introduction to how a SQL engine handles a query.
The query normally goes through 5 different phases:
1) Receive query on the client connection
2) Query parsing
3) Query optimisation
4) Query execution
5) Send result of query on client connection
The result of 1) is a text string that contains the SQL query to
execute. In this simplistic view of the SQL engine we will ignore
any such things as prepared statements and other things making the
model more complex.
The text string is parsed by 2) into a data structure that represents
the query in objects that match concepts in the SQL engine.
Query optimisation takes this data structure as input and creates a
new data structure that contains an executable query plan.
Query execution uses the data structure from the query optimisation
phase to execute the query.
Query execution produces a set of result rows that is sent back to the
client.
In the MySQL Server those phases isn't completely sequential, there are
many different optimisations that occurs in all phases. However for this
description it is accurate enough.
When we started working on the plan to develop a way to allow the storage
engine to take over parts of the query, we concluded that the storage
engine should use an Abstract Query Plan of some sort.
We decided early on to only push joins down after the query optimisation
phase. There could be some additional benefits of this, but the project
was sufficiently complex to handle anyways.
We see how the pushdown of a join into the storage engine happens:
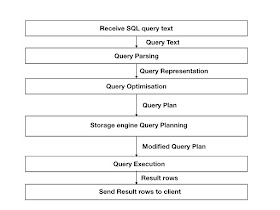
As can be seen the storage engine receives the Query Plan as input and
produces a modified query plan as output. In addition the storage engine
creates an internal plan for how to execute the query internally.
NDB is involved in the Query Optimisation phase in the normal manner handled
by the MySQL Server. This means that NDB has to keep index statistics up to
date. A new feature can also be used to improve the cost model in MySQL 8.0.
This is to generate histograms on individual columns, this feature works per
MySQL Server and is generated by an SQL command. We will show a few examples
later on how this can be used to improve performance of queries.
MySQL uses a cost model, and this cost model works fairly well for NDB as well
even though NDB is a distributed storage engine. There is some improvements
possible in the exactness of the NDB index statistics, but the model as such
works well enough.
Examples of ways to change the query plan is when we push a condition
to the storage engine, in this case the query condition can be removed
from the query plan used by the MySQL Server. The internal query plan
contains information of join order, pushed conditions, linked reads
from a table earlier in the join order to a later table in the join
order. Some parts of the internal query execution can be modified as
the query is executed. Examples of such things is the parallelism used
in the query. This can be optimised to make optimal use of the server
resources (CPU, memory, disks and networks).
The storage engine can select to handle the join partially or fully.
Taking care of a pushdown partially can be down both on condition level
as well as on a table level.
So as an example if we have a condition that cannot be pushed to NDB, this
condition will not be pushed, but the table can still be pushed to NDB.
If we have a 6-way join and the third table in the join for some reason
cannot be pushed to NDB, then we can still push the join of the first two
tables, the result of those two tables joined is then joined inside the
MySQL server and finally the results are fed into the last 3-way join that
is also pushed to NDB.
One common case where a query can be pushed in multiple steps into NDB is
when the query contains a subquery. We will look into such an example
in a later blog.
So in conclusion the join pushdown works by first allowing the MySQL Server
to create an optimal execution plan. Next we attempt to push as many parts
down to the NDB storage engine as possible.
The idea with the pushdown is to be able to get more batching happening.
For example if we have a key lookup in one of the tables in the join it is not
possible to handle more than one row at a time using the MySQL Server whereas
with pushdown we can handle hundreds of key lookups in parallel.
Another reason is that by moving the join operator into the data node we come
closer to the data. This avoids a number of messages back and forth between the
MySQL Server and the data nodes.
Finally by moving the join operator down into the data nodes we can even have
multiple join operators. This can be used also for other things than the join operator
in the future such as aggregation, sorting and so forth.
An alternative approach would be to push the entire query down to NDB when it
works. The NDB model with join pushdown of full or partial parts of the
queries however works very well for the NDB team. We are thus able to develop
improvements of the join pushdown in a stepwise approach and even without being
able to push the full query we can still improve the query substantially.
As an example Q12 was not completely pushed before MySQL Cluster 8.0.18. Still
pushing only parts of it made a speedup of 20x possible, when the final step
of comparing two columns was added in 8.0.18 the full improvement of 40x
was made possible.
Next part
.........
In the next part we will describe how NDB handle batches, this has an important
impact on the possible parallelism in query execution.
2-way join query from TPC-H. In this part we will describe how
the pushdown of joins to a storage engine works in the MySQL Server.
First a quick introduction to how a SQL engine handles a query.
The query normally goes through 5 different phases:
1) Receive query on the client connection
2) Query parsing
3) Query optimisation
4) Query execution
5) Send result of query on client connection
The result of 1) is a text string that contains the SQL query to
execute. In this simplistic view of the SQL engine we will ignore
any such things as prepared statements and other things making the
model more complex.
The text string is parsed by 2) into a data structure that represents
the query in objects that match concepts in the SQL engine.
Query optimisation takes this data structure as input and creates a
new data structure that contains an executable query plan.
Query execution uses the data structure from the query optimisation
phase to execute the query.
Query execution produces a set of result rows that is sent back to the
client.
In the MySQL Server those phases isn't completely sequential, there are
many different optimisations that occurs in all phases. However for this
description it is accurate enough.
When we started working on the plan to develop a way to allow the storage
engine to take over parts of the query, we concluded that the storage
engine should use an Abstract Query Plan of some sort.
We decided early on to only push joins down after the query optimisation
phase. There could be some additional benefits of this, but the project
was sufficiently complex to handle anyways.
We see how the pushdown of a join into the storage engine happens:

As can be seen the storage engine receives the Query Plan as input and
produces a modified query plan as output. In addition the storage engine
creates an internal plan for how to execute the query internally.
NDB is involved in the Query Optimisation phase in the normal manner handled
by the MySQL Server. This means that NDB has to keep index statistics up to
date. A new feature can also be used to improve the cost model in MySQL 8.0.
This is to generate histograms on individual columns, this feature works per
MySQL Server and is generated by an SQL command. We will show a few examples
later on how this can be used to improve performance of queries.
MySQL uses a cost model, and this cost model works fairly well for NDB as well
even though NDB is a distributed storage engine. There is some improvements
possible in the exactness of the NDB index statistics, but the model as such
works well enough.
Examples of ways to change the query plan is when we push a condition
to the storage engine, in this case the query condition can be removed
from the query plan used by the MySQL Server. The internal query plan
contains information of join order, pushed conditions, linked reads
from a table earlier in the join order to a later table in the join
order. Some parts of the internal query execution can be modified as
the query is executed. Examples of such things is the parallelism used
in the query. This can be optimised to make optimal use of the server
resources (CPU, memory, disks and networks).
The storage engine can select to handle the join partially or fully.
Taking care of a pushdown partially can be down both on condition level
as well as on a table level.
So as an example if we have a condition that cannot be pushed to NDB, this
condition will not be pushed, but the table can still be pushed to NDB.
If we have a 6-way join and the third table in the join for some reason
cannot be pushed to NDB, then we can still push the join of the first two
tables, the result of those two tables joined is then joined inside the
MySQL server and finally the results are fed into the last 3-way join that
is also pushed to NDB.
One common case where a query can be pushed in multiple steps into NDB is
when the query contains a subquery. We will look into such an example
in a later blog.
So in conclusion the join pushdown works by first allowing the MySQL Server
to create an optimal execution plan. Next we attempt to push as many parts
down to the NDB storage engine as possible.
The idea with the pushdown is to be able to get more batching happening.
For example if we have a key lookup in one of the tables in the join it is not
possible to handle more than one row at a time using the MySQL Server whereas
with pushdown we can handle hundreds of key lookups in parallel.
Another reason is that by moving the join operator into the data node we come
closer to the data. This avoids a number of messages back and forth between the
MySQL Server and the data nodes.
Finally by moving the join operator down into the data nodes we can even have
multiple join operators. This can be used also for other things than the join operator
in the future such as aggregation, sorting and so forth.
An alternative approach would be to push the entire query down to NDB when it
works. The NDB model with join pushdown of full or partial parts of the
queries however works very well for the NDB team. We are thus able to develop
improvements of the join pushdown in a stepwise approach and even without being
able to push the full query we can still improve the query substantially.
As an example Q12 was not completely pushed before MySQL Cluster 8.0.18. Still
pushing only parts of it made a speedup of 20x possible, when the final step
of comparing two columns was added in 8.0.18 the full improvement of 40x
was made possible.
Next part
.........
In the next part we will describe how NDB handle batches, this has an important
impact on the possible parallelism in query execution.
No comments:
Post a Comment