When you run MySQL on a large NUMA box it is possible to control the memory placement and the use of CPUs through the use of numactl. Most modern servers are NUMA boxes nowadays.
numactl works with a concept called NUMA nodes. One NUMA node contains CPUs and memory where all the CPUs can access the memory in this NUMA node at an equal delay. However to access memory in a different NUMA node will typically be slower and it can often be 50% or even 100% slower to access memory in a different NUMA node compared to the local NUMA node. One NUMA node is typically one chip with a memory bus shared by all CPU cores in the chip. There can be multiple chips in one socket.
With numactl the default option is to allocate memory from the NUMA node the CPU currently running on is connected to. There is also an option to interleave memory allocation on the different parts of the machine by using the interleave option.
Memory allocation actually happens in two steps. The first step is the one that makes a call to malloc. This invokes a library linked with your application, this could be e.g. the libc library or a library containing tcmalloc or jemalloc or some other malloc implementation. The malloc implementation is very important for performance of the MySQL Server, but in most cases the malloc library doesn't control the placement of the allocated memory.
The allocation of physical memory happens when the memory area is touched, either the first time or after the memory have been swapped out and a page fault happens. This is the time that we assign memory to the actual NUMA node it's going to be allocated on. To control how the Linux OS decides on this memory allocation one can use the numactl program.
numactl provides options to decide on whether to use interleaved memory location or local memory. The problem with local memory can be easily seen if we consider that the first thing that happens in the MySQL Server is a recovery of the InnoDB and this recovery is single-threaded so will thus make a large piece of the memory in the buffer pool to be attached to the NUMA node where the recovery took place. Using interleaved allocation means that we get a better spread of the memory allocation.
We can also use the interleave option to specify which NUMA nodes the memory should be chosen from. Thus the interleave option acts both as a way of binding the MySQL Server to NUMA nodes as well as interleaving memory allocation on all the NUMA nodes the server is bound to.
numactl finally also provides an ability to bind the MySQL Server to specific CPUs in the computer. This can be either by locking to NUMA nodes, or by locking to individual CPU cores.
So e.g. on a machine with 8 NUMA nodes one might start the MySQL Server like this:
numactl --interleave=2-7 --cpunodebind=2-7 mysqld ....
This will allow the benchmark program to use NUMA node 0 and 1 without interfering with the MySQL Server program. If we want to use the normal local memory allocation it should more or less be sufficient to remove the interleave option since we have bound the MySQL Server to NUMA node 2-7 there should be very slim risk that the memory is allocated from elsewhere. We could however also use
--memnodebind=2-7 to ensure that the memory allocation happens in the desired NUMA nodes.
So how effective is numactl compared to e.g. using taskset. From a benchmark performance point of view there is not much difference unless you get memory very unbalanced through a long recovery at the start of the MySQL Server. Given that taskset allows the server to be bound to certain CPU cores, it also means effectively that the memory is bound to the NUMA nodes of the CPUs the MySQL Server was bound to by taskset.
However binding to a subset of the NUMA nodes or CPUs in the computer is definitely a good idea. On a large NUMA box one can gain at least 10% performance by locking to a subset of the machine compared to allowing the MySQL Server to freely use the entire machine.
Binding the MySQL Server also improves the stability of the performance. Also binding to certain CPUs can be an instrument in ensuring that different appplications running on the same computer don't interfere with each other. Naturally this can also be done by using virtual machines.
Tuesday, December 21, 2010
Tuesday, November 30, 2010
The King is dead, long live the King
In MySQL 5.5 we introduced a possibility to use alternative malloc implementations for MySQL. In Solaris we have found mtmalloc to be the optimal malloc implementation. For Linux we've previously found tcmalloc to be the optimal malloc implementation. However recently when working on a new MySQL feature I discovered a case where tcmalloc had a performance regression after running a very tough benchmark for about an hour. Actually I found a similar issue with the standard libc malloc implementation. So it seems that many malloc implementations gets into fragmentation issues when running for an extended period at very high load.
So I decided to contact Mark Callaghan to see if he had seen similar issues. He hadn't, but he pointed me towards an alternative malloc implementation which is jemalloc. It turns out that jemalloc is the malloc implementation used in FreeBSD among other things. I found a downloadable tarball of jemalloc, downloaded it and installed it on my benchmark computers. Given that MySQL already supports any generic malloc implementation it was a simple matter of pointing LD_PRELOAD towards jemalloc instead of towards tcmalloc to make this experiment.
The background is that tcmalloc gave about +5-10% better performance than libc malloc on Linux. Both libc malloc and tcmalloc have had performance regressions in certain situations. So the new results for jemalloc was very exciting. I got +15% compared to libc malloc and so far after using it for about a month I have found no performance regressions using jemalloc.
So I decided to contact Mark Callaghan to see if he had seen similar issues. He hadn't, but he pointed me towards an alternative malloc implementation which is jemalloc. It turns out that jemalloc is the malloc implementation used in FreeBSD among other things. I found a downloadable tarball of jemalloc, downloaded it and installed it on my benchmark computers. Given that MySQL already supports any generic malloc implementation it was a simple matter of pointing LD_PRELOAD towards jemalloc instead of towards tcmalloc to make this experiment.
The background is that tcmalloc gave about +5-10% better performance than libc malloc on Linux. Both libc malloc and tcmalloc have had performance regressions in certain situations. So the new results for jemalloc was very exciting. I got +15% compared to libc malloc and so far after using it for about a month I have found no performance regressions using jemalloc.
Thursday, October 28, 2010
Impact of changes in the run-time environment of MySQL 5.5
When experimenting with the Google patches a few years ago I found that tcmalloc had a fairly large impact on performance of the MySQL Server. So the question I asked myself was obviously whether the libc malloc have regained some of the lost territory (also had regressions of major drop in performance in certain libc versions). Using tcmalloc used to have a 5-10% positive impact on performance, the matter of the fact is that this gain remains. I lost 8-10% in performance on all thread counts tested (16, 32, 64, 128 and 256) by not using tcmalloc in running Sysbench RW.
The experiments are performed on a fairly high-end x86 box with 4 sockets. I run the sysbench program on the same machine as the MySQL Server runs on. So this means that it's interesting to check whether I get better performance by locking the MySQL Server to 3 of the 4 sockets and let sysbench use its own socket compared to not control CPU usage at all.
What I discovered is a mixed picture. Performance when locking to CPU's was much more stable although top performance was better without locking. Performance at 16 threads improved 3% and at 32 threads it improved 7%. But at higher thread counts the performance was better for the locked scenario, 10% at 64 threads and 4% at 256 threads. I used the Linux feature taskset to lock the MySQL Server and Sysbench to certain CPUs.
So the conclusion is that locking to CPUs gives a more stable environment. When the number of threads increases the scheduler is allowed to use more CPUs than what is beneficial for MySQL execution. I've seen this also in other experiments that making sure that MySQL reuses the CPU caches as much as possible is very important for performance. Thus when MySQL competes with other programs on use of CPUs and there are many concurrent MySQL threads it's usually not beneficial to performance since the CPU caches will be too cold.
Using Unix sockets instead of TCP/IP sockets is very beneficial for MySQL performance still. I haven't made any recent experiments in this area but the difference is definitely significant. I have also seen OS bottlenecks sometimes appear when using TCP/IP sockets. This is an area for further investigation which I have had on my TODO list for a while. It's also interesting to experiment with different communication mechanisms when the Sysbench program and MySQL runs on different computers. However this is for future testing.
The experiments are performed on a fairly high-end x86 box with 4 sockets. I run the sysbench program on the same machine as the MySQL Server runs on. So this means that it's interesting to check whether I get better performance by locking the MySQL Server to 3 of the 4 sockets and let sysbench use its own socket compared to not control CPU usage at all.
What I discovered is a mixed picture. Performance when locking to CPU's was much more stable although top performance was better without locking. Performance at 16 threads improved 3% and at 32 threads it improved 7%. But at higher thread counts the performance was better for the locked scenario, 10% at 64 threads and 4% at 256 threads. I used the Linux feature taskset to lock the MySQL Server and Sysbench to certain CPUs.
So the conclusion is that locking to CPUs gives a more stable environment. When the number of threads increases the scheduler is allowed to use more CPUs than what is beneficial for MySQL execution. I've seen this also in other experiments that making sure that MySQL reuses the CPU caches as much as possible is very important for performance. Thus when MySQL competes with other programs on use of CPUs and there are many concurrent MySQL threads it's usually not beneficial to performance since the CPU caches will be too cold.
Using Unix sockets instead of TCP/IP sockets is very beneficial for MySQL performance still. I haven't made any recent experiments in this area but the difference is definitely significant. I have also seen OS bottlenecks sometimes appear when using TCP/IP sockets. This is an area for further investigation which I have had on my TODO list for a while. It's also interesting to experiment with different communication mechanisms when the Sysbench program and MySQL runs on different computers. However this is for future testing.
Finding the optimum configuration of MySQL 5.5 running Sysbench
Sysbench is a commonly used benchmark tool to discover ways to improve MySQL performance. It is certainly not representative for every application, but it's still a useful tool for finding bottlenecks in the MySQL code.
In MySQL 5.5 a great number of new scalability improvements have been developed. Some of these will always be active and some of them requires using new configuration parameters.
In order to assist users of MySQL I am performing a fairly extensive benchmark series where I test the various configuration parameters that have an effect on running MySQL/InnoDB using Sysbench.
The parameters can be categorized into:
1) Changes of run-time environment
2) Compile time parameters (including choice of compiler)
3) Configuration parameters for MySQL
4) Configuration parameters for InnoDB
Finally there is also a set of parameters one can use to affect the execution of sysbench itself to have it behave differently. It's possible to have Sysbench use secondary index instead of primary key index, it's possible to let the table be partitioned and it's possible to run sysbench using multiple tables instead of only one (it's very syntetic to only have one table in a system which gets all the queries).
The parameters that I have found to be important to consider for performance of MySQL 5.5 when running sysbench are:
1.1) Use of tcmalloc
1.2) Use of taskset (lock MySQL to certain CPUs)
1.3) Affecting memory allocation by use of numactl
1.4) Connecting to MySQL through socket or using TCP/IP
2.1) Use of gcc compiler with platform-specific optimisations
2.2) Use --with-fast-mutexes flag when compiling MySQL
2.3) Choice of compiler (gcc, Open64, icc, SunStudio, ..)
2.4) Using feedback compilation in compilation
2.5) Compiling sysbench itself with platform specific optimisations
3.1) Choice of transaction isolation (READ COMMITTED or REPEATABLE READ)
3.2) Use of large pages through setting --large-pages=ON
3.3) Compiling with Performance Schema activated
3.4) Running with Performance Schema activated through --perfschema
3.5) Deactivating Query Cache completely through --query_cache_size=0
and --query_cache_type=0
4.1) Using new file format Barracuda or old format Antelope through
--innodb_file_format=x
4.2) Setting --innodb_stats_on_metadata to ON/OFF
4.3) Deactivating InnoDB doublewrite through --skip-innodb_doublewrite
4.4) Setting innodb-change-buffering to none/insert/all and so forth
4.5) Setting number of buffer pool instances using innodb-buffer-pool-instances=x
4.6) Setting InnoDB log file size using innodb-log-file-size=x
4.7) Setting InnoDB log buffer size using innodb-log-buffer-size=x
4.8) Setting InnoDB flush method (default fsync, O_DIRECT, O_DSYNC) using
--innodb_flush_method=x
4.9) Setting InnoDB to use file per table using --innodb_file_per_table
4.10) Deactivating InnoDB adaptive hash index using
--skip-innodb-adaptive-hash-index
4.11) Adapting read-ahead using --innodb_read_ahead=x
4.12) Using InnoDB max purge lag through --innodb_max_purge_lag=x
4.13) Using InnoDB purge thread through --innodb_purge_thread=1
4.14) Changing behaviour of InnoDB spin loops by changing
--innodb_sync_spin_loops=x and --innodb_spin_wait_delay=x
4.15) Changing InnoDB IO capacity by setting --innodb-io-capacity=x
4.16) Setting InnoDB buffer pool size through --innodb-buffer-pool-size=x
4.17) Setting InnoDB dirty pages percent through --innodb_dirty_pages_pct=x
4.18) Setting InnoDB old blocks percentage through --innodb_old_blocks_pct=x
4.19) Activating support for InnoDB XA through --innodb_support_xa=FALSE/TRUE
4.20) Activating InnoDB thread concurrency using
--innodb-thread-concurrency=x
4.21) Setting InnoDB commit mechanism through
--innodb-flush-log-at-trx-commit=x
4.22) Setting number of read and write IO threads through
--innodb-read-io-threads=x and --innodb-write-io-threads=x
This makes for a total of 36 parameters that can be tuned to affect sysbench performance. Most of these parameters have only a limited impact on performance but some of them can have a large impact and there is also a number of them where most reasonable values are ok, but if a bad value is used it can have a major impact on performance.
In addition the problem of finding the optimal values is a multi-dimensional search. So changing one parameter might very well affect the impact of other parameters. So my approach will be to start with a reasonable baseline configuration, then try each parameter and see how it affects the outcome, come to a new baseline by changing the most important parameter. Next step is to restart tests varying all the parameters which have had a measurable impact on performance. Using this method we should be able to find an optimum to a reasonable degree. Finding the absolute optimum is probably more or less practically impossible.
It's important here to understand that the MySQL defaults can sometimes have really bad values for performance. The reason is that MySQL defaults have been choosen mainly to make MySQL run on any HW platform and use very small resources. Remember that the normal use of MySQL isn't running sysbench on a 32-core server :) So it is important to consider all of these parameters to get the optimal performance of the MySQL Server.
I plan to write about these variables and how they affect sysbench performance in a number of upcoming blogs. I might also do a similar run with MySQL using the DBT2 benchmark. So hopefully after finishing these test runs I have found a reasonable optimum configuration to run sysbench and probably also the configuration parameters that needs changing when running DBT2 instead.
In MySQL 5.5 a great number of new scalability improvements have been developed. Some of these will always be active and some of them requires using new configuration parameters.
In order to assist users of MySQL I am performing a fairly extensive benchmark series where I test the various configuration parameters that have an effect on running MySQL/InnoDB using Sysbench.
The parameters can be categorized into:
1) Changes of run-time environment
2) Compile time parameters (including choice of compiler)
3) Configuration parameters for MySQL
4) Configuration parameters for InnoDB
Finally there is also a set of parameters one can use to affect the execution of sysbench itself to have it behave differently. It's possible to have Sysbench use secondary index instead of primary key index, it's possible to let the table be partitioned and it's possible to run sysbench using multiple tables instead of only one (it's very syntetic to only have one table in a system which gets all the queries).
The parameters that I have found to be important to consider for performance of MySQL 5.5 when running sysbench are:
1.1) Use of tcmalloc
1.2) Use of taskset (lock MySQL to certain CPUs)
1.3) Affecting memory allocation by use of numactl
1.4) Connecting to MySQL through socket or using TCP/IP
2.1) Use of gcc compiler with platform-specific optimisations
2.2) Use --with-fast-mutexes flag when compiling MySQL
2.3) Choice of compiler (gcc, Open64, icc, SunStudio, ..)
2.4) Using feedback compilation in compilation
2.5) Compiling sysbench itself with platform specific optimisations
3.1) Choice of transaction isolation (READ COMMITTED or REPEATABLE READ)
3.2) Use of large pages through setting --large-pages=ON
3.3) Compiling with Performance Schema activated
3.4) Running with Performance Schema activated through --perfschema
3.5) Deactivating Query Cache completely through --query_cache_size=0
and --query_cache_type=0
4.1) Using new file format Barracuda or old format Antelope through
--innodb_file_format=x
4.2) Setting --innodb_stats_on_metadata to ON/OFF
4.3) Deactivating InnoDB doublewrite through --skip-innodb_doublewrite
4.4) Setting innodb-change-buffering to none/insert/all and so forth
4.5) Setting number of buffer pool instances using innodb-buffer-pool-instances=x
4.6) Setting InnoDB log file size using innodb-log-file-size=x
4.7) Setting InnoDB log buffer size using innodb-log-buffer-size=x
4.8) Setting InnoDB flush method (default fsync, O_DIRECT, O_DSYNC) using
--innodb_flush_method=x
4.9) Setting InnoDB to use file per table using --innodb_file_per_table
4.10) Deactivating InnoDB adaptive hash index using
--skip-innodb-adaptive-hash-index
4.11) Adapting read-ahead using --innodb_read_ahead=x
4.12) Using InnoDB max purge lag through --innodb_max_purge_lag=x
4.13) Using InnoDB purge thread through --innodb_purge_thread=1
4.14) Changing behaviour of InnoDB spin loops by changing
--innodb_sync_spin_loops=x and --innodb_spin_wait_delay=x
4.15) Changing InnoDB IO capacity by setting --innodb-io-capacity=x
4.16) Setting InnoDB buffer pool size through --innodb-buffer-pool-size=x
4.17) Setting InnoDB dirty pages percent through --innodb_dirty_pages_pct=x
4.18) Setting InnoDB old blocks percentage through --innodb_old_blocks_pct=x
4.19) Activating support for InnoDB XA through --innodb_support_xa=FALSE/TRUE
4.20) Activating InnoDB thread concurrency using
--innodb-thread-concurrency=x
4.21) Setting InnoDB commit mechanism through
--innodb-flush-log-at-trx-commit=x
4.22) Setting number of read and write IO threads through
--innodb-read-io-threads=x and --innodb-write-io-threads=x
This makes for a total of 36 parameters that can be tuned to affect sysbench performance. Most of these parameters have only a limited impact on performance but some of them can have a large impact and there is also a number of them where most reasonable values are ok, but if a bad value is used it can have a major impact on performance.
In addition the problem of finding the optimal values is a multi-dimensional search. So changing one parameter might very well affect the impact of other parameters. So my approach will be to start with a reasonable baseline configuration, then try each parameter and see how it affects the outcome, come to a new baseline by changing the most important parameter. Next step is to restart tests varying all the parameters which have had a measurable impact on performance. Using this method we should be able to find an optimum to a reasonable degree. Finding the absolute optimum is probably more or less practically impossible.
It's important here to understand that the MySQL defaults can sometimes have really bad values for performance. The reason is that MySQL defaults have been choosen mainly to make MySQL run on any HW platform and use very small resources. Remember that the normal use of MySQL isn't running sysbench on a 32-core server :) So it is important to consider all of these parameters to get the optimal performance of the MySQL Server.
I plan to write about these variables and how they affect sysbench performance in a number of upcoming blogs. I might also do a similar run with MySQL using the DBT2 benchmark. So hopefully after finishing these test runs I have found a reasonable optimum configuration to run sysbench and probably also the configuration parameters that needs changing when running DBT2 instead.
Wednesday, September 22, 2010
How to speed up Sysbench on MySQL Cluster by 14x
The time period up to the 2010 MySQL Users conference was as usual packed with hard work. The last two conferences have been very focused on getting scalability of the MySQL Server and InnoDB improved. This year had a nasty surprise after the conference in the form of ash cloud from an icelandic volcano. When you're tired from hard work and just want to go home and get some rest then the concept of staying at a hotel room with absolutely no idea of when one could return home is no fun at all. So when I finally returned home I was happy that summer was close by, vacation days were available (swedes have a lot of vacation :)).
Now the summer is gone and I am rested up again, ready to take on new challenges and we've had some really interesting meet-ups in the MySQL team to discuss future developments. The renewed energy also is sufficient to write up some of the stories from the work I did during the summer :)
During the summer I had the opportunity to also get some work done on scalability of the MySQL Cluster product as well. Given that I once was the founder of this product it was nice to return again and check where it stands in scalability terms.
The objective was to compare MySQL Cluster to the Memory engine. The result of the exercise was almost obvious from the start. The memory engine having a table lock will have very limited scalability on any workload that contains writes. It will however have very good scalability on read-only workloads as this isn't limited by the table lock since readers don't contend each other. The Cluster engine should have good and fairly even results on read and write workloads.
Much to my surprise the early results showed a completely different story. The Memory engine gave me a performance of about 1-2 tps to start with. The early results of MySQL Cluster was also very dismaying. I covered the Memory engine in a previous blog, so in this blog I will focus on the MySQL Cluster benchmarks.
So the simple task of benchmarking as usual turned into some debugging of where the performance problems comes from.
In the first experiment I used the default configuration of the Fedora Linux OS, I also used the default set-up of the MySQL Cluster storage engine. It turned out that there are huge possibilities in adapting those defaults.
First the Fedora has a feature called cpuspeed. By default this feature is activated. The feature provides power management by scaling down the CPU frequency on an entire socket. The problem is that when you run the MySQL Server with few threads, it doesn't react to the workload and scales down frequency although there is a lot of work to do. So for the MySQL Server in general this means about half the throughput on up to 16 threads. However the impact on MySQL Cluster is even worse. The performance drops severely on all thread counts. Most likely this impact comes from the very short execution times of the NDB data nodes. It's possible that this small execution times is too short to even reach the radar of the power management tools in Linux.
So a simple sudo /etc/init.d/cpuspeed stop generated a major jump in performance of the MySQL Cluster in a simple Sysbench benchmark (all the benchmarks discussed here used 1 data node and all things running on one machine unless otherwise stated).
The next simple step was to add the MySQL Cluster configuration parameter MaxNoOfExecutionThreads to the configuration scripts and set this to the maximum which is 8. This means that one thread will handle receive on the sockets, one thread will handle transaction coordination and four threads will handle local database handling. There will also be a couple of other threads which are of no importance to a benchmark.
These two configuration together added about ~3.5x in increased performance. Off to a good start, but still performance isn't at all where I want it to be.
In NDB there is a major scalability bottleneck in the mutex protecting all socket traffic. It's the NDB API's variant of the big kernel mutex. There is however one method of decreasing the impact of this mutex by turning the MySQL Server into several client nodes from an NDB perspective. This is done by adding the --ndb-cluster-connection-pool parameter when starting the MySQL Server. We achieved the best performance when setting this to 8, in a bigger cluster it would probably make more sense to set it to 2 or 3 since this resolves most of the scalability issues without using up so much nodes in the NDB cluster.
Changing this from 1 to 8 added another ~2x in performance. So now the performance is up a decent 8x from the first experiments. No wonder I was dismayed by the early results.
However the story isn't done yet :)
MySQL Cluster has another feature whereby the various threads can be locked to CPUs. By using this feature we can achieve two things, the first is that the NDB data nodes doesn't share CPUs with the MySQL Server. This has some obvious benefits from CPU cache point of view for both node types. We can also avoid that the data node threads are moved from CPU to CPU which is greatly advantegous in busy workloads. So we locked the data nodes to 6 cores. The configuration variable we used to achieve this is LockExecuteThreadToCpu which is set to a comma separated list of CPU ids.
I also locked the MySQL Server and Sysbench to different set of CPUs using the taskset program available in Linux.
Using this locking of NDB data node threads to CPUs achieved another 80% boost in performance. So the final result gave us a decent 14x performance improvement.
So in summary things that matters greatly to performance of MySQL Cluster for Sysbench with a single data node.
1) Ensure the Linux cpuspeed isn't activated
2) Make sure to set MaxNoOfExecutionThreads to 8
3) Make sure the --ndb-cluster-configuration-pool parameter to the MySQL Server using around 8 nodes per MySQL Server
4) Lock NDB Data node threads to CPUs by using the LockExecuteThreadToCpu.
5) Lock MySQL Server and Sysbench processes to different sets of CPUs from NDB Data nodes and each other.
Doing this experiments also generated a lot of interesting ideas on how to improve things even further.
Now the summer is gone and I am rested up again, ready to take on new challenges and we've had some really interesting meet-ups in the MySQL team to discuss future developments. The renewed energy also is sufficient to write up some of the stories from the work I did during the summer :)
During the summer I had the opportunity to also get some work done on scalability of the MySQL Cluster product as well. Given that I once was the founder of this product it was nice to return again and check where it stands in scalability terms.
The objective was to compare MySQL Cluster to the Memory engine. The result of the exercise was almost obvious from the start. The memory engine having a table lock will have very limited scalability on any workload that contains writes. It will however have very good scalability on read-only workloads as this isn't limited by the table lock since readers don't contend each other. The Cluster engine should have good and fairly even results on read and write workloads.
Much to my surprise the early results showed a completely different story. The Memory engine gave me a performance of about 1-2 tps to start with. The early results of MySQL Cluster was also very dismaying. I covered the Memory engine in a previous blog, so in this blog I will focus on the MySQL Cluster benchmarks.
So the simple task of benchmarking as usual turned into some debugging of where the performance problems comes from.
In the first experiment I used the default configuration of the Fedora Linux OS, I also used the default set-up of the MySQL Cluster storage engine. It turned out that there are huge possibilities in adapting those defaults.
First the Fedora has a feature called cpuspeed. By default this feature is activated. The feature provides power management by scaling down the CPU frequency on an entire socket. The problem is that when you run the MySQL Server with few threads, it doesn't react to the workload and scales down frequency although there is a lot of work to do. So for the MySQL Server in general this means about half the throughput on up to 16 threads. However the impact on MySQL Cluster is even worse. The performance drops severely on all thread counts. Most likely this impact comes from the very short execution times of the NDB data nodes. It's possible that this small execution times is too short to even reach the radar of the power management tools in Linux.
So a simple sudo /etc/init.d/cpuspeed stop generated a major jump in performance of the MySQL Cluster in a simple Sysbench benchmark (all the benchmarks discussed here used 1 data node and all things running on one machine unless otherwise stated).
The next simple step was to add the MySQL Cluster configuration parameter MaxNoOfExecutionThreads to the configuration scripts and set this to the maximum which is 8. This means that one thread will handle receive on the sockets, one thread will handle transaction coordination and four threads will handle local database handling. There will also be a couple of other threads which are of no importance to a benchmark.
These two configuration together added about ~3.5x in increased performance. Off to a good start, but still performance isn't at all where I want it to be.
In NDB there is a major scalability bottleneck in the mutex protecting all socket traffic. It's the NDB API's variant of the big kernel mutex. There is however one method of decreasing the impact of this mutex by turning the MySQL Server into several client nodes from an NDB perspective. This is done by adding the --ndb-cluster-connection-pool parameter when starting the MySQL Server. We achieved the best performance when setting this to 8, in a bigger cluster it would probably make more sense to set it to 2 or 3 since this resolves most of the scalability issues without using up so much nodes in the NDB cluster.
Changing this from 1 to 8 added another ~2x in performance. So now the performance is up a decent 8x from the first experiments. No wonder I was dismayed by the early results.
However the story isn't done yet :)
MySQL Cluster has another feature whereby the various threads can be locked to CPUs. By using this feature we can achieve two things, the first is that the NDB data nodes doesn't share CPUs with the MySQL Server. This has some obvious benefits from CPU cache point of view for both node types. We can also avoid that the data node threads are moved from CPU to CPU which is greatly advantegous in busy workloads. So we locked the data nodes to 6 cores. The configuration variable we used to achieve this is LockExecuteThreadToCpu which is set to a comma separated list of CPU ids.
I also locked the MySQL Server and Sysbench to different set of CPUs using the taskset program available in Linux.
Using this locking of NDB data node threads to CPUs achieved another 80% boost in performance. So the final result gave us a decent 14x performance improvement.
So in summary things that matters greatly to performance of MySQL Cluster for Sysbench with a single data node.
1) Ensure the Linux cpuspeed isn't activated
2) Make sure to set MaxNoOfExecutionThreads to 8
3) Make sure the --ndb-cluster-configuration-pool parameter to the MySQL Server using around 8 nodes per MySQL Server
4) Lock NDB Data node threads to CPUs by using the LockExecuteThreadToCpu.
5) Lock MySQL Server and Sysbench processes to different sets of CPUs from NDB Data nodes and each other.
Doing this experiments also generated a lot of interesting ideas on how to improve things even further.
How to get Sysbench on Memory engine to perform
I had the opportunity to test the Memory engine during the summer. What I expected to be a very simple exercise in running the Sysbench benchmark turned out to be a lot more difficult than I expected.
My first experiments with the Memory engine gave very dismaying results. I got 0-2 TPS which is ridiculously bad. So I couldn't really think this was proper results, so I started searching for problems in my benchmarking environment. Eventually I started setting up a normal MySQL client session to the MySQL Server while the benchmark was running and issued some of the queries in the benchmark by hand and I was surprised to see some simple queries take seconds.
EXPLAIN came to my rescue. EXPLAIN showed that the range scans in Sysbench was in fact turned into full table scans. Now this was surprising given that the primary key index in most engines is always ordered, so a range scan should normally be translated to a simple ordered index scan.
What I found is that the Memory engine has a different default compared to the other storage engines. When we designed the NDB handler we decided that any SQL users expects to have an ordered index when they create an index on a table. Since primary key indexes are always hash-based, this meant that in NDB the default primary key index is actually two indexes, one primary hash index and one secondary ordered index on the same fields.
Not so in the Memory engine. The memory engine also uses a hash-based index by default. So when you create a new index on a Memory engine and specify no type, the index wil become a hash index. Hash indexes are not very good at range queries :) so thus the surprise to me when benchmarking the Memory engine in Sysbench.
Fixing this issue required some code changes in the sysbench test. It required the proposed fix from Mark Callaghan to add secondary indexes to sysbench. This was however not sufficient since this patch only added an index by adding KEY xid (id) and didn't specifically specify this index had to be an ordered index. So I changed this to KEY xid (id) USING BTREE and off the performance went.
The Memory engine is still more or less a single threaded engine for any write workload like Sysbench RW which limits performance very much.
However the Sysbench Readonly benchmark for the Memory engine was interesting since it used no limiting locks (concurrent readers don't contend with each other). I decided to see how much scalability was achievable for a storage engine without any concurrency issues internally.
I found that performance of the Memory engine was limited to 8% more than the InnoDB engine in the same benchmark. So my interpretation of this result is that for readonly workloads, the main limiting factor on scalability is the MySQL Server scalability issues and not the InnoDB ones.
So going forward when working on further improving the scalability of the MySQL Server parts there is a perfect benchmark that can be used to see how scalable the MySQL Server part is by using the Memory engine.
I plan on also adding a feature to sysbench making it possible to use more than one Sysbench table to see how much added scalability we get when there are several tables involved in the query mix. Sysbench is a a very syntectic benchmark in this manner that it only uses one table.
Only using one table provokes more bottlenecks than is found in most normal workloads, e.g. the LOCK_open in the MySQL Server, the meta data locks introduced in MySQL 5.5, the index mutex in InnoDB and even some unbalance to the usage of multiple buffer pools come from only using one table in the benchmark.
My first experiments with the Memory engine gave very dismaying results. I got 0-2 TPS which is ridiculously bad. So I couldn't really think this was proper results, so I started searching for problems in my benchmarking environment. Eventually I started setting up a normal MySQL client session to the MySQL Server while the benchmark was running and issued some of the queries in the benchmark by hand and I was surprised to see some simple queries take seconds.
EXPLAIN came to my rescue. EXPLAIN showed that the range scans in Sysbench was in fact turned into full table scans. Now this was surprising given that the primary key index in most engines is always ordered, so a range scan should normally be translated to a simple ordered index scan.
What I found is that the Memory engine has a different default compared to the other storage engines. When we designed the NDB handler we decided that any SQL users expects to have an ordered index when they create an index on a table. Since primary key indexes are always hash-based, this meant that in NDB the default primary key index is actually two indexes, one primary hash index and one secondary ordered index on the same fields.
Not so in the Memory engine. The memory engine also uses a hash-based index by default. So when you create a new index on a Memory engine and specify no type, the index wil become a hash index. Hash indexes are not very good at range queries :) so thus the surprise to me when benchmarking the Memory engine in Sysbench.
Fixing this issue required some code changes in the sysbench test. It required the proposed fix from Mark Callaghan to add secondary indexes to sysbench. This was however not sufficient since this patch only added an index by adding KEY xid (id) and didn't specifically specify this index had to be an ordered index. So I changed this to KEY xid (id) USING BTREE and off the performance went.
The Memory engine is still more or less a single threaded engine for any write workload like Sysbench RW which limits performance very much.
However the Sysbench Readonly benchmark for the Memory engine was interesting since it used no limiting locks (concurrent readers don't contend with each other). I decided to see how much scalability was achievable for a storage engine without any concurrency issues internally.
I found that performance of the Memory engine was limited to 8% more than the InnoDB engine in the same benchmark. So my interpretation of this result is that for readonly workloads, the main limiting factor on scalability is the MySQL Server scalability issues and not the InnoDB ones.
So going forward when working on further improving the scalability of the MySQL Server parts there is a perfect benchmark that can be used to see how scalable the MySQL Server part is by using the Memory engine.
I plan on also adding a feature to sysbench making it possible to use more than one Sysbench table to see how much added scalability we get when there are several tables involved in the query mix. Sysbench is a a very syntectic benchmark in this manner that it only uses one table.
Only using one table provokes more bottlenecks than is found in most normal workloads, e.g. the LOCK_open in the MySQL Server, the meta data locks introduced in MySQL 5.5, the index mutex in InnoDB and even some unbalance to the usage of multiple buffer pools come from only using one table in the benchmark.
Saturday, September 18, 2010
Multiple Buffer Pools in MySQL 5.5
In our work to improve MySQL scalability we tested many opportunities to scale the MySQL Server and the InnoDB storage engine. The InnoDB buffer pool was often one of the hottest contention points in the server. This is very natural since every access to a data page, UNDO page, index page uses the buffer pool and even more so when those pages are read from disk and written to disk.
As usual there were two ways to split the buffer pool mutex, one way is to split it functionally into different mutexes protecting different parts. There have been experiments in particular on splitting out the buffer pool page hash table, the flush list. Other parts that have been broken out in experiments are the LRU list, the free list and other data structures internally in the buffer pool. Additionally it is as usual possible to split the buffer pool into multiple buffer pools. Interestingly one can also combine using multiple buffer pools with splitting the buffer pool mutex into smaller parts. The advantage of using multiple buffer pools is that it is very rare that it is necessary to grab multiple mutexes for the buffer pool operation which quickly becomes the case when splitting the buffer pool into multiple mutex protection areas.
After working on scalability improvements in MySQL and InnoDB I noted that all the discussion was around how to split the buffer pool mutex and no dicsussion centered around how to make multiple buffer pools out of the buffer pool. I decided to investigate how difficult it would be to make this change. I quickly realised that it needed a thorugh walk through of the code. It required a code check that required checking about 150 methods and their interaction. This sounds like a very big task, but fortunately the InnoDB code is well structured and have fairly simple dependencies between its methods. After this walk through of the buffer pool code one quickly found that there were 3 different ways of getting hold of the buffer pool, one method was to calculate it using the space id and page id. This is the normal method in most methods used in the external buffer pool interface. However there were numerous occasions where we only had access to the block or page data structure and it would be a bit useless to recalculate the hash value in every method that needed access to the buffer pool data structure. So it was decided to leave a reference to the buffer pool in every page data structure. There were also a few occasions where one needed to access all buffer pools.
The analysis proved that most of the accesses to the buffer pool was completely independent of other accesses to the buffer pool for other pages. InnoDB uses read-ahead and neighbour writes in the IO operations that are started from the buffer pool. These always operate on an extent of 64 pages. Thus it made sense to map the pages of 64 pages into one buffer pool to avoid having to operate on multiple buffer pools on every IO operation.
With these design ideas there were only a few occasions where it was necessary to operate on all buffer pools. One such operation was when the log required knowledge of the page with the oldest LSN of the buffer pool. Now this operation requires looping over all buffer pools and checking the minimum LSN of each buffer pool instance. This is a fairly rare operation so isn't a scalability issue.
The other operation with requirement to loop over all pages needed a bit more care, this operation is the background operation flushing buffer pool pages to disk. A couple of problems needs consideration here. First it is necessary to flush pages regularly from all buffer pool instances, secondly it's still important to flush neighbours. Given that many disks are fairly slow, it can be problematic to spread the load in this manner to many buffer pools. This is an important consideration when deciding how many buffer pool instances to configure.
The default number of buffer pool is one and for most small configurations with less than 8 cores it's mostly a good idea not to increase this value. If you have an installation that uses 8 cores or more one should also pay attention to the disk subsystem that is used. Given that InnoDB often writes up to 64 neighbours in each operation and that the flushing should happen each second, it makes sense to have a disk subsystem capable of having 500 IO operations per second to use 8 buffer pool instances. This can be set in the innodb_io_capacity configuration variable. One SSD drive should be capable of handling this, two fast hard drives or 3 slow ones.
In our experiments we have mostly used 8 buffer pools, more buffer pools can be useful at times. The main problem with many buffer pools is related to the IO operations. It is important to have a balanced IO load in the MySQL server.
Our analysis of using multiple buffer pool instances have shown some interesting facts. First the accesses to the buffer pools is in no way evenly spread out. This is not surprising given that e.g. the root page of an index is a very frequently accessed page. So using sysbench with only one table, there will obviously be much more accesses to certain buffer pool instances. Our experiments shows that in sysbench using 8 buffer pools, the hottest buffer pool receives about one third of all accesses. Given that sysbench is a worst case scenario for the multiple buffer pool case, this means that most applications that tend to use more tables and more indexes should have a much more even load on the buffer pools.
So how much does multiple buffer pools improve the scalability of the MySQL Server. The answer is as usual dependent on application, OS, HW and so forth. But some general ideas can be found from our experiments. In sysbench using a load which is entirely held in main memory, so the disk is only used for flushing data pages and logging, in this system the multiple buffer pools can provide up to 10% improvement of the throughput in the system. In dbStress, the benchmark Dimitri uses, we have seen all the way up to 30% improvement. The reason here is most likely that dbStress uses more tables and have avoided many other bottlenecks in the MySQL Server and thus the buffer pool was a worse bottleneck in dbStress compared to sysbench. From the code it is also easy to see that the more IO operations the buffer pool performs, the more the buffer pool mutex will be acquired and also often held for a longer time. One such example is the search for a free page on the LRU list every time a read is performed into the buffer pool from the disk.
Furthermore the use of multiple buffer pool opens up for many more improvements and also it doesn't remove the possibility to split the buffer pool mutex even more.
Another manner of displaying the importance of using multiple buffer pools is the mutex statistics on the buffer pool mutex. With one buffer pool the buffer pool had about 750k accesses per second in a sysbench test where the MySQL Server had access to 16 cores. 50% of those accesses met a mutex already held, so it's obvious that the InnoDB mutex subsystem is very well aligned with the buffer pool mutex which have very short duration which makes spinning waiting for it very fruitful. Anyways a mutex which is held 50% of the time makes the buffer pool mutex a limiting factor of the MySQL Server. Quite a few threads will often spend time in the queue waiting for the buffer pool mutex. So splitting the buffer pool into 8 instances even in sysbench means that the hottest buffer pool receives about one third of the 750k accesses so should be held about 17% of the time. Our later experiments shows that the hottest buffer pool mutexes are now held up to about 14-15% of the time. So the theory matches the real world fairly well. This means that the buffer pool is still a major factor in the MySQL Scalability equation but is now more on par with the other bottlenecks in the MySQL Server.
The development project of multiple buffer pools happened at a time when the MySQL and InnoDB teams could start working together. I was impressed by the willingness to cooperate and the competence in the InnoDB team that made it possible to introduce multiple buffer pools into MySQL 5.5. Our cooperation has continued since then and this has led to improvements in productivity on both parts. So for you as a MySQL user this spells good times going forward.
As usual there were two ways to split the buffer pool mutex, one way is to split it functionally into different mutexes protecting different parts. There have been experiments in particular on splitting out the buffer pool page hash table, the flush list. Other parts that have been broken out in experiments are the LRU list, the free list and other data structures internally in the buffer pool. Additionally it is as usual possible to split the buffer pool into multiple buffer pools. Interestingly one can also combine using multiple buffer pools with splitting the buffer pool mutex into smaller parts. The advantage of using multiple buffer pools is that it is very rare that it is necessary to grab multiple mutexes for the buffer pool operation which quickly becomes the case when splitting the buffer pool into multiple mutex protection areas.
After working on scalability improvements in MySQL and InnoDB I noted that all the discussion was around how to split the buffer pool mutex and no dicsussion centered around how to make multiple buffer pools out of the buffer pool. I decided to investigate how difficult it would be to make this change. I quickly realised that it needed a thorugh walk through of the code. It required a code check that required checking about 150 methods and their interaction. This sounds like a very big task, but fortunately the InnoDB code is well structured and have fairly simple dependencies between its methods. After this walk through of the buffer pool code one quickly found that there were 3 different ways of getting hold of the buffer pool, one method was to calculate it using the space id and page id. This is the normal method in most methods used in the external buffer pool interface. However there were numerous occasions where we only had access to the block or page data structure and it would be a bit useless to recalculate the hash value in every method that needed access to the buffer pool data structure. So it was decided to leave a reference to the buffer pool in every page data structure. There were also a few occasions where one needed to access all buffer pools.
The analysis proved that most of the accesses to the buffer pool was completely independent of other accesses to the buffer pool for other pages. InnoDB uses read-ahead and neighbour writes in the IO operations that are started from the buffer pool. These always operate on an extent of 64 pages. Thus it made sense to map the pages of 64 pages into one buffer pool to avoid having to operate on multiple buffer pools on every IO operation.
With these design ideas there were only a few occasions where it was necessary to operate on all buffer pools. One such operation was when the log required knowledge of the page with the oldest LSN of the buffer pool. Now this operation requires looping over all buffer pools and checking the minimum LSN of each buffer pool instance. This is a fairly rare operation so isn't a scalability issue.
The other operation with requirement to loop over all pages needed a bit more care, this operation is the background operation flushing buffer pool pages to disk. A couple of problems needs consideration here. First it is necessary to flush pages regularly from all buffer pool instances, secondly it's still important to flush neighbours. Given that many disks are fairly slow, it can be problematic to spread the load in this manner to many buffer pools. This is an important consideration when deciding how many buffer pool instances to configure.
The default number of buffer pool is one and for most small configurations with less than 8 cores it's mostly a good idea not to increase this value. If you have an installation that uses 8 cores or more one should also pay attention to the disk subsystem that is used. Given that InnoDB often writes up to 64 neighbours in each operation and that the flushing should happen each second, it makes sense to have a disk subsystem capable of having 500 IO operations per second to use 8 buffer pool instances. This can be set in the innodb_io_capacity configuration variable. One SSD drive should be capable of handling this, two fast hard drives or 3 slow ones.
In our experiments we have mostly used 8 buffer pools, more buffer pools can be useful at times. The main problem with many buffer pools is related to the IO operations. It is important to have a balanced IO load in the MySQL server.
Our analysis of using multiple buffer pool instances have shown some interesting facts. First the accesses to the buffer pools is in no way evenly spread out. This is not surprising given that e.g. the root page of an index is a very frequently accessed page. So using sysbench with only one table, there will obviously be much more accesses to certain buffer pool instances. Our experiments shows that in sysbench using 8 buffer pools, the hottest buffer pool receives about one third of all accesses. Given that sysbench is a worst case scenario for the multiple buffer pool case, this means that most applications that tend to use more tables and more indexes should have a much more even load on the buffer pools.
So how much does multiple buffer pools improve the scalability of the MySQL Server. The answer is as usual dependent on application, OS, HW and so forth. But some general ideas can be found from our experiments. In sysbench using a load which is entirely held in main memory, so the disk is only used for flushing data pages and logging, in this system the multiple buffer pools can provide up to 10% improvement of the throughput in the system. In dbStress, the benchmark Dimitri uses, we have seen all the way up to 30% improvement. The reason here is most likely that dbStress uses more tables and have avoided many other bottlenecks in the MySQL Server and thus the buffer pool was a worse bottleneck in dbStress compared to sysbench. From the code it is also easy to see that the more IO operations the buffer pool performs, the more the buffer pool mutex will be acquired and also often held for a longer time. One such example is the search for a free page on the LRU list every time a read is performed into the buffer pool from the disk.
Furthermore the use of multiple buffer pool opens up for many more improvements and also it doesn't remove the possibility to split the buffer pool mutex even more.
Another manner of displaying the importance of using multiple buffer pools is the mutex statistics on the buffer pool mutex. With one buffer pool the buffer pool had about 750k accesses per second in a sysbench test where the MySQL Server had access to 16 cores. 50% of those accesses met a mutex already held, so it's obvious that the InnoDB mutex subsystem is very well aligned with the buffer pool mutex which have very short duration which makes spinning waiting for it very fruitful. Anyways a mutex which is held 50% of the time makes the buffer pool mutex a limiting factor of the MySQL Server. Quite a few threads will often spend time in the queue waiting for the buffer pool mutex. So splitting the buffer pool into 8 instances even in sysbench means that the hottest buffer pool receives about one third of the 750k accesses so should be held about 17% of the time. Our later experiments shows that the hottest buffer pool mutexes are now held up to about 14-15% of the time. So the theory matches the real world fairly well. This means that the buffer pool is still a major factor in the MySQL Scalability equation but is now more on par with the other bottlenecks in the MySQL Server.
The development project of multiple buffer pools happened at a time when the MySQL and InnoDB teams could start working together. I was impressed by the willingness to cooperate and the competence in the InnoDB team that made it possible to introduce multiple buffer pools into MySQL 5.5. Our cooperation has continued since then and this has led to improvements in productivity on both parts. So for you as a MySQL user this spells good times going forward.
Split log_sys mutex in MySQL 5.5
One important bottleneck in the MySQL Server is the log_sys mutex in InnoDB. Experiments using mutex statistics showed that this mutex was accessed about 250k times per second and that about 75% of those accesses had to queue up to get the mutex. One particular nuisance is that while holding the log_sys mutex it is necessary to grab the buffer pool mutex to put the changed pages to the start of the flush list indicating it is now the youngest dirty page in the buffer pool (this happens as part of the mini commit functionality in InnoDB). To some extent this contention point is decreased by splitting out the buffer flush list from the buffer pool mutex.
We found a simple improvement of this particular problem. The simple solution is to introduce a new mutex, log_flush_order mutex, this mutex is acquired while still holding the log_sys mutex, as soon as it is acquired we can release the log_sys mutex. This gives us the property that the log_sys mutex is available for other operations such as starting a new log write while we still serialise the input of the dirty pages into the buffer pool flush list.
As can be easily seen this solution decrease the hold time of the log_sys mutex while not decreasing the frequency it is acquired.
In our experiments we saw that this very simple solution improved a Sysbench RW test by a few percent.
We found a simple improvement of this particular problem. The simple solution is to introduce a new mutex, log_flush_order mutex, this mutex is acquired while still holding the log_sys mutex, as soon as it is acquired we can release the log_sys mutex. This gives us the property that the log_sys mutex is available for other operations such as starting a new log write while we still serialise the input of the dirty pages into the buffer pool flush list.
As can be easily seen this solution decrease the hold time of the log_sys mutex while not decreasing the frequency it is acquired.
In our experiments we saw that this very simple solution improved a Sysbench RW test by a few percent.
Tuesday, April 13, 2010
Scalability enhancements of MySQL 5.5.4-m3
The MySQL 5.5.4-m3 beta version contains a number of
interesting new scalability features.
It contains the following InnoDB improvements:
Multiple Buffer Pool instances
- For example if the buffer pool is 8 GByte in size
the buffer pool can be split into 4 buffer pools
each containing 2 GBytes. Each page is mapped into
one and only one of these buffer pools.
Split Log_sys mutex
- We have ensured that the Log mutex and the buffer
pool mutex is more independent of each other. Also
the log_sys mutex is through this split less
contended.
Split out flush list from buffer pool mutex
Split Rollback Segment mutex into 128 instances
Separate Purge Thread from Master Thread
- Splitting out the purge thread from the master thread
is very important to ensure that performance is stable.
Extended Change buffering, now also Deletes and purges are
possible to buffer.
It contains the following MySQL Server improvements:
Split LOCK_open into
- MDL hash mutex
- MDL table lock mutex
- atomic variable refresh_version
- LOCK_open
We also removed some parts not needing mutex
protection from LOCK_open. All these mutexes are taken
independently of each other in almost all places.
Remove LOCK_alarm (used in network handling)
Remove LOCK_thread_count as scalability bottleneck
In addition the InnoDB recovery has been improved by
decreasing recovery time by 10x.
interesting new scalability features.
It contains the following InnoDB improvements:
Multiple Buffer Pool instances
- For example if the buffer pool is 8 GByte in size
the buffer pool can be split into 4 buffer pools
each containing 2 GBytes. Each page is mapped into
one and only one of these buffer pools.
Split Log_sys mutex
- We have ensured that the Log mutex and the buffer
pool mutex is more independent of each other. Also
the log_sys mutex is through this split less
contended.
Split out flush list from buffer pool mutex
Split Rollback Segment mutex into 128 instances
Separate Purge Thread from Master Thread
- Splitting out the purge thread from the master thread
is very important to ensure that performance is stable.
Extended Change buffering, now also Deletes and purges are
possible to buffer.
It contains the following MySQL Server improvements:
Split LOCK_open into
- MDL hash mutex
- MDL table lock mutex
- atomic variable refresh_version
- LOCK_open
We also removed some parts not needing mutex
protection from LOCK_open. All these mutexes are taken
independently of each other in almost all places.
Remove LOCK_alarm (used in network handling)
Remove LOCK_thread_count as scalability bottleneck
In addition the InnoDB recovery has been improved by
decreasing recovery time by 10x.
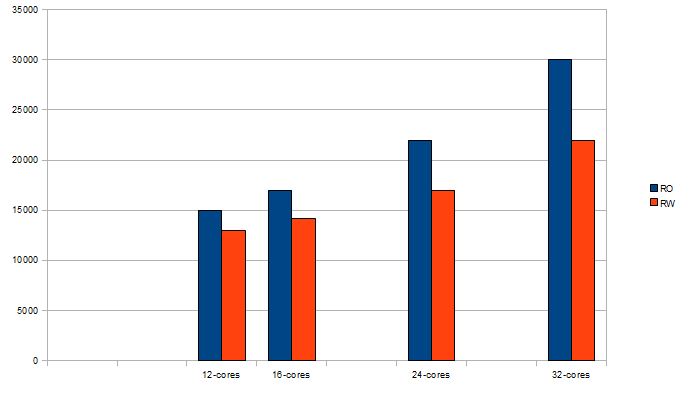
MySQL 5.5.4-m3 scales to 32 cores
The newly released MySQL 5.5 beta version MySQL 5.5.4-m3
has a large number of significant performance improvements.
These improvements makes it possible for MySQL to scale
well even on 32-core servers. The graph below shows how
MySQL 5.5.4-m3 scales from 12 cores to 32 cores using a
single thread per core. The benchmark used here is
dbStress. dbStress uses a number of tables which spreads
the impact of mutexes and improves scalability.

The graph below shows a similar scalability analysis on a
smaller server where the benchmark used was Sysbench RW.
The red line shows the scalability of MySQL 5.1.45, the
green line shows scalability of MySQL 5.5.3-m3 and the
blue line shows MySQL 5.5.4-m3. So this graph shows that
even with a single table in Sysbench RW we are able to
scale very well to 16 cores. The graph also displays how
our work on scaling MySQL since the release of MySQL 5.1
as GA in december 2008 is paying off in a significant
manner. So MySQL is following very well in the development
of new multi-core CPUs. The major performance enhancement
in MySQL 5.5.3-m3 is the use of the InnoDB plugin with
its inclusion of Google patches and other significant
enhancements to InnoDB. MySQL 5.5.4-m3 contains a large
number of new scalability enhancements that will be
explained more about on this blog.

has a large number of significant performance improvements.
These improvements makes it possible for MySQL to scale
well even on 32-core servers. The graph below shows how
MySQL 5.5.4-m3 scales from 12 cores to 32 cores using a
single thread per core. The benchmark used here is
dbStress. dbStress uses a number of tables which spreads
the impact of mutexes and improves scalability.
The graph below shows a similar scalability analysis on a
smaller server where the benchmark used was Sysbench RW.
The red line shows the scalability of MySQL 5.1.45, the
green line shows scalability of MySQL 5.5.3-m3 and the
blue line shows MySQL 5.5.4-m3. So this graph shows that
even with a single table in Sysbench RW we are able to
scale very well to 16 cores. The graph also displays how
our work on scaling MySQL since the release of MySQL 5.1
as GA in december 2008 is paying off in a significant
manner. So MySQL is following very well in the development
of new multi-core CPUs. The major performance enhancement
in MySQL 5.5.3-m3 is the use of the InnoDB plugin with
its inclusion of Google patches and other significant
enhancements to InnoDB. MySQL 5.5.4-m3 contains a large
number of new scalability enhancements that will be
explained more about on this blog.
